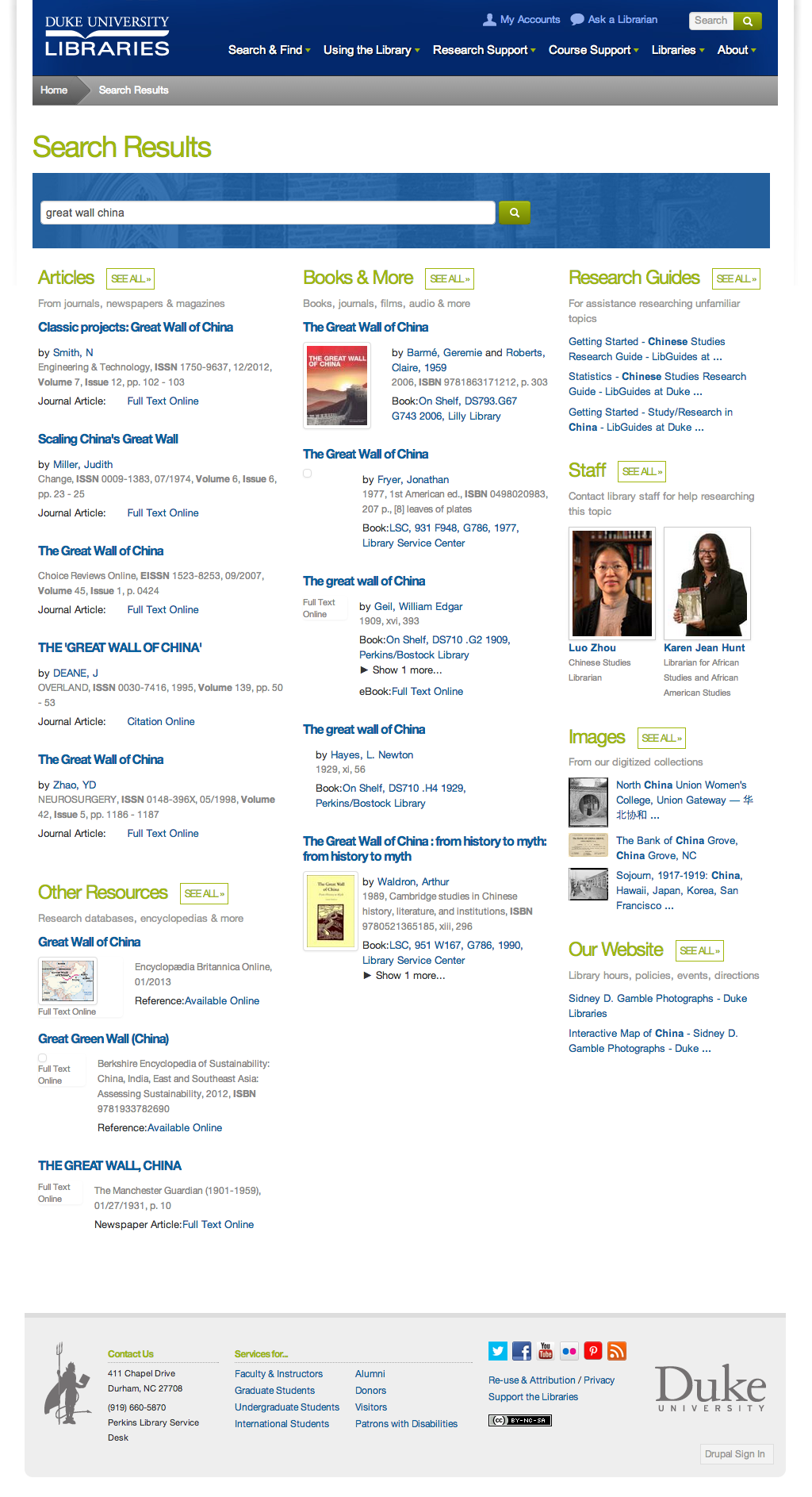
This fall we changed the default tool that students and faculty use to research library holdings. We have tools that work well for a broad search and tools that are tailored for more specialized research. So, how is this change working out?
Word cloud depicting the 30 most frequently used search terms. The size of the text is proportional to the number of times the term has been used.
We’ve got numbers and we’ve got opinion. First, let’s look at the numbers.
The most used feature on the Duke Libraries website is the search box on the homepage with 211,655 searches performed using the default “All” tab between August 25 and November 16, 2014.
Within the “All” tab search results, patrons selected results from Articles 48% of the time, results from Books & Media 44% of the time and other results 8% of the time. These results were presented side-by-side on a single results page.
The All search isn’t the only option on our homepage as the Books & Media tab was used 68,566 times and the Articles tab was used 46,028 times during the same timeframe.
The five most used search terms were PubMed, Web of Science, JSTOR, RefWorks, and Dictionary of National Biography.
The most frequently searched for fictional character was Tom Sawyer.
The most searched for person was Dr. Martin Luther King, Jr.
So what thoughts have you shared with us about the search options we provide?
On the Libraries’ homepage, you can click the gear icon to choose a different search tab as your customized default.
During the first four weeks of the semester, 48 people submitted their opinions through a survey linked from the search results page.
Thirty percent of survey respondents said that they liked having the Articles and Books & Media results appear side by side on the new search results page.
Twenty-seven percent said they thought the page looked cluttered or that it was hard to read.
Forty percent said that they did not know you can change the default search tab that appears when you view the Duke Libraries’ homepage.
Twenty-five percent said that they did not know that they can choose a more highly-focused search option from the Search & Find menu.
Testing with a small group of researchers revealed that it was difficult to locate material from the Rubenstein Library using our default search results screen.
Based on your feedback, we made the following improvements to the search results page during the semester.
We de-cluttered the information shown in the Articles and Books & Media columns to make results easier to read.
We moved “Our Website” results to the top of the right column.
We reduced the space used by the search box on the results page.
In the coming months, we will explore ways of making it easier to find materials from the Rubenstein Library and from University Archives. We are also investigating options for implementing a Best Bets feature on the results page; this would provide clearer access to some of the most used resources.
What can you do to help?
Complete our online survey and tell us what you think about the search tools provided through the Libraries’ homepage.
I’ve had the pleasure of working on several exhibit kiosks during my time at the library. Most of them have been simple in their functionality, but we’re hoping to push some boundaries and get more creative in the future. Most recently, I’ve been working on building a kiosk for the Queering Duke History: Understanding the LGBTQ Experience at Duke and Beyond exhibit. It highlights oral history interviews with six former Duke students. This particular kiosk example isn’t very complicated, but I thought it would be fun to outline how it’s put together.
Screen shot of the ‘attract’ loop
Hardware
Most of our exhibits run on one of two late 2009 27″ iMacs that we have at our disposal. The displays are high-res (1920×1080) and vivid, the built-in speakers sound fine, and the processors are strong enough to display multimedia content without any trouble. Sometimes we use the kiosk machines to loop video content, so there’s no user interaction required. With this latest iteration, as users will be able to select audio files for playback, we’ll need to provide a mouse. We do our best to secure them to our kiosk stand, and in my tenure we’ve not had any problems. But I understand in the past that sometimes input devices have been damaged or gone missing. As we migrate to touch-screen machines in the future these sorts of issues won’t be a problem.
Software
We tend to leave our kiosk machines out in the open in public spaces. If the machine isn’t sufficiently locked down, it can lead to it being used for purposes other than what we have in mind. Our approach is to setup a user account that has very narrow privileges and set it as the default login (so when the machine starts up it boots into our ‘kiosk’ account). In OS X you can setup user permissions, startup programs, and other settings via ‘Users and Groups’ in the System Preferences. We also setup power saving settings so that the computer will sleep between midnight and 6:00am using the Energy Saving Scheduler.
My general approach for interactive content is to build web pages, host them externally, and load them on to the kiosk in a web browser. I think the biggest benefits of this approach are that we can make updates without having to take down the kiosk and also track user interactions using Google analytics. However, there are drawbacks as well. We need to ensure that we have reliable network connectivity, which can be a challenge sometimes. By placing the machine online, we also add to the risk that it can be used for purposes other than what we intend. So in order to lock things down even more, we utilize xStand to display our interactive content. It allows for full screen browsing without any GUI chrome, black-listing and/or white-listing sites, and most importantly, it restarts automatically after a crash. In my experience it’s worked very well.
User Interface
This particular exhibit kiosk has only one real mission – to enable users to listen to a series of audio clips. As such, the UI is very simple. The first component is a looping ‘attract’ screen. The attract screen serves the dual purpose of drawing attention to the kiosk and keeping pixels from getting burned in on the display. For this kiosk I’m looping a short mp4 video file. The video container is wrapped in a link and when it’s clicked a javscript hides the video and displays the content div.
The content area of the page is very simple – there are a group of images that can be clicked on. When they are, a lightbox window (I like Fancy Box) pops up that holds the relevant audio clips. I’m using simple html5 audio playback controls to stream the mp3 files.
Screen shot of the ‘home’ screen UIScreen shot of the audio playback UI
Finally, there’s another javascript running in the background that detects and user input. After 10 minutes of inactivity, the page reloads which brings back the attract screen.
The Exhibit
Queering Duke History runs through December 14, 2014 in the Perkins Library Gallery on West Campus. Stop by and check it out!
We’ve written many posts on this blog that describe (in detail) how we build our digital collections at Duke, how we describe them, and how we make them accessible to researchers.
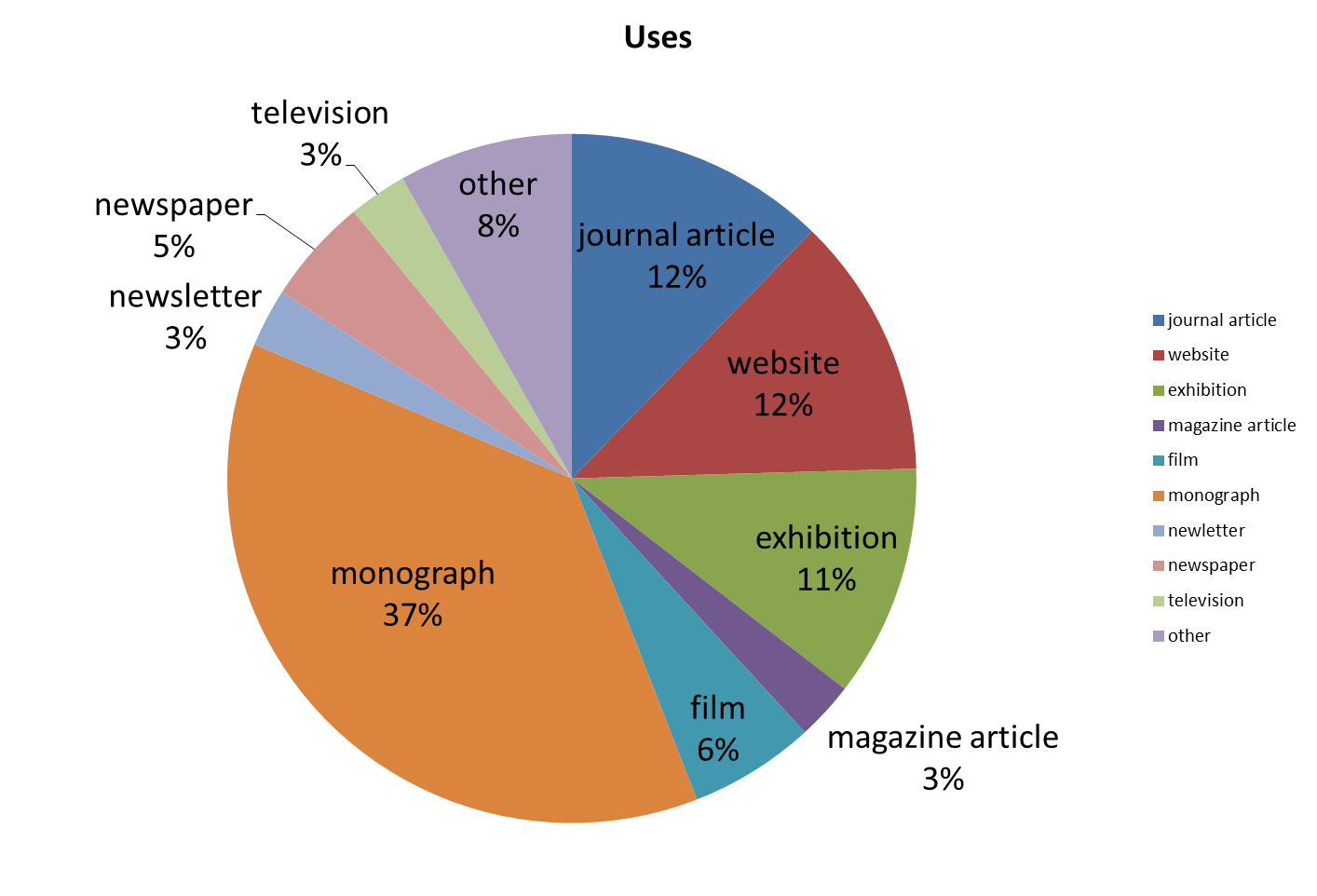
At a Rubenstein Library staff meeting this morning one of my colleagues–Sarah Carrier–gave an interesting report on how some of our researchers are actually using our digital collections. Sarah’s report focused specifically on permission-to-publish requests, that is, cases where researchers requested permission from the library to publish reproductions of materials in our collection in scholarly monographs, journal articles, exhibits, websites, documentaries, and any number of other creative works. To be clear, Sarah examined all of these requests, not just those involving digital collections. Below is a chart showing the distribution of the types of publication uses.
Types of permission-to-publish requests, FY2013-2014
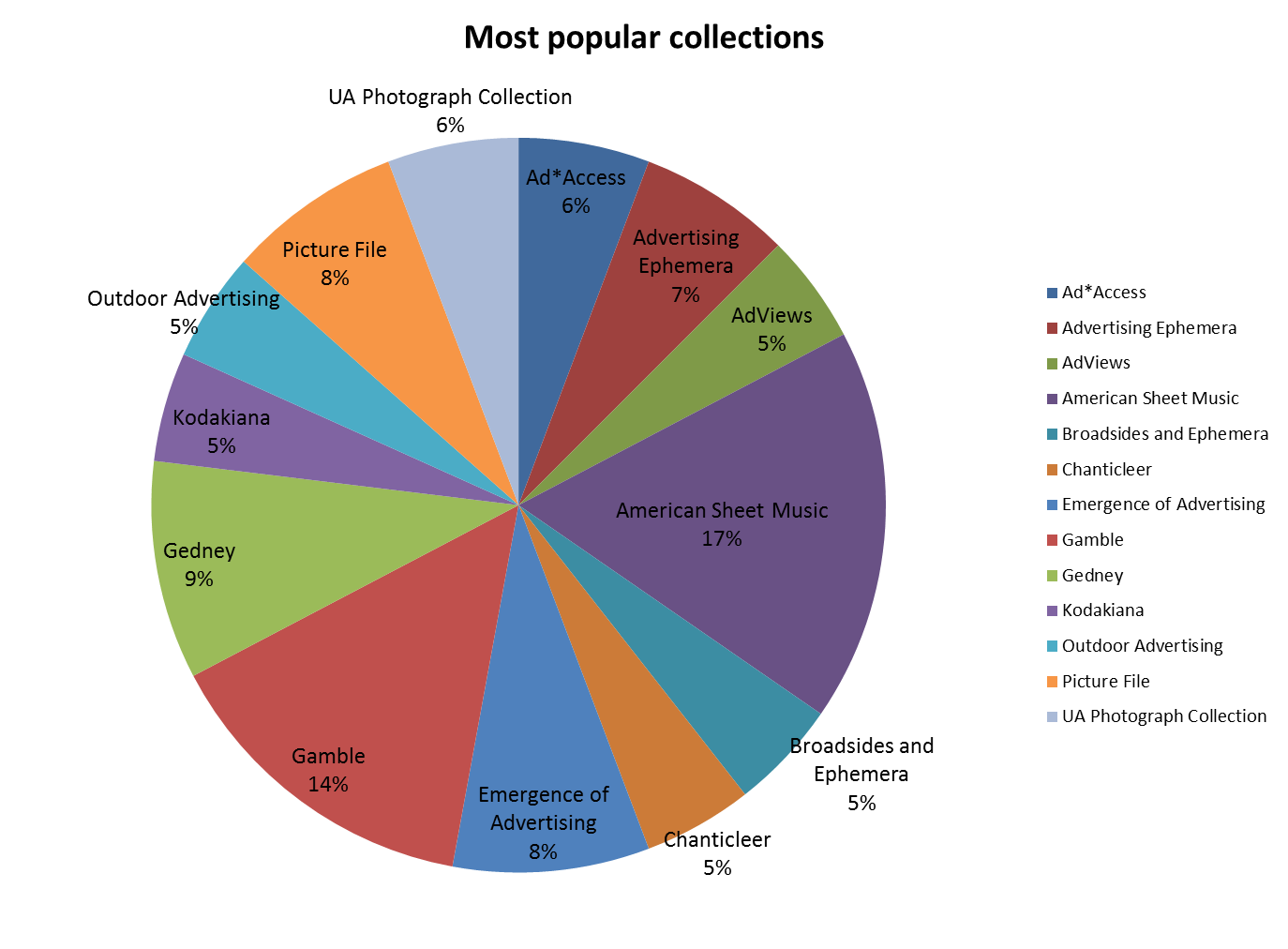
What I found especially interesting about Sarah’s report, though, is that nearly 76% of permission-to-publish requests did involve materials from the Rubenstein that have been digitized and are available in Duke Digital Collections. The chart below shows the Rubenstein collections that generate the highest percentage of requests. Notice that three of these in Duke Digital Collections were responsible for 40% of all permission-to-publish requests:
Collections generating the most permission-to-publish requests, FY2013-2014
So, even though we’ve only digitized a small fraction of the Rubenstein’s holdings (probably less than 1%), it is this 1% that generates the overwhelming majority of permission-to-publish requests.
I find this stat both encouraging and discouraging at the same time. On one hand, it’s great to see that folks are finding our digital collections and using them in their publications or other creative output. On the other hand, it’s frightening to think that the remainder of our amazing but yet-to-be digitized collections are rarely if ever used in publications, exhibits, and websites.
I’m not suggesting that researchers aren’t using un-digitized materials. They certainly are, in record numbers. More patrons are visiting our reading room than ever before. So how do we explain these numbers? Perhaps research and publication are really two separate processes. Imagine you’ve just written a 400 page monograph on the evolution of popular song in America, you probably just want to sit down at your computer, fire up your web browser, and do a Google Image Search for “historic sheet music” to find some cool images to illustrate your book. Maybe I’m wrong, but if I’m not, we’ve got you covered. After it’s published, send us a hard copy. We’ll add it to the collection and maybe we’ll even digitize it someday.
[Data analysis and charts provided by Sarah Carrier – thanks Sarah!]
Back in February 2014, we wrapped up the CCC project, a collaborative three year IMLS-funded digitization initiative with our partners in the Triangle Research Libraries Network (TRLN). The full title of the project is a mouthful, but it captures its essence: “Content, Context, and Capacity: A Collaborative Large-Scale Digitization Project on the Long Civil Rights Movement in North Carolina.”
So how large is “large-scale”? By comparison, when the project kicked off in summer 2011, we had a grand total of 57,000 digitized objects available online (“published”), collectively accumulated through sixteen years of digitization projects. That number was 69,000 by the time we began publishing CCC manuscripts in June 2012. Putting just as many documents online in three years as we’d been able to do in the previous sixteen naturally requires a much different approach to creating digital collections.
Traditional Digitization
Large-Scale Digitization
Individual items identified during scanning
No item-level identification: entire folders scanned
Descriptive metadata applied to each item
Archival description only (e.g., at the folder level)
Digitized documents accessed through an archival finding aid / collection guide with folder-level description.
Project Evaluation
CCC staff completed qualitative and quantitative evaluations of this large-scale digitization approach during the course of the project, ranging from conducting user focus groups and surveys to analyzing the impact on materials prep time and image quality control. Researcher assessments targeted three distinct user groups: 1) Faculty & History Scholars; 2) Undergraduate Students (in research courses at UNC & NC State); 3) NC Secondary Educators.
Ease of Use. Faculty and scholars, for the most part, found it easy to use digitized content presented this way. Undergraduates were more ambivalent, and secondary educators had the most difficulty.
To Embed or Not to Embed. In 2012, Duke was the only library presenting the image thumbnails embedded directly within finding aids and a lightbox-style image navigator. Undergrads who used Duke’s interface found it easier to use than UNC or NC Central’s, and Duke’s collections had a higher rate of images viewed per folder than the other partners. UNC & NC Central’s interfaces now use a similar convention.
Potential for Use. Most users surveyed said they could indeed imagine themselves using digitized collections presented in this way in the course of their research. However, the approach falls short in meeting key needs for secondary educators’ use of primary sources in their classes.
Desired Enhancements. The top two most desired features by faculty/scholars and undergrads alike were 1) the ability to search the text of the documents (OCR), and 2) the ability to explore by topic, date, document type (i.e., things enabled by item-level metadata). PDF download was also a popular pick.
Impact on Duke Digitization Projects
Since the moment we began putting our CCC manuscripts online (June 2012), we’ve completed the eight CCC collections using this large-scale strategy, and an additional eight manuscript collections outside of CCC using the same approach. We have now cumulatively put more digital objects online using the large-scale method (96,000) than we have via traditional means (75,000). But in that time, we have also completed eleven digitization projects with traditional item-level identification and description.
We see the large-scale model for digitization as complementary to our existing practices: a technique we can use to meet the publication needs of some projects.
Usage
Do people actually use the collections when presented in this way? Some interesting figures:
Views / item in 2013-14 (traditional digital object; item-level description): 13.2
Views / item in 2013-14 (digitized image within finding aid; folder-level description): 1.0
Views / folder in 2013-14 (digitized folder view in finding aid): 8.5
It’s hard to attribute the usage disparity entirely to the publication method (they’re different collections, for one). But it’s reasonable to deduce (and unsurprising) that bypassing item-level description generally results in less traffic per item.
On the other hand, one of our CCC collections (The Allen Building Takeover Collection) has indeed seen heavy use–so much, in fact, that nearly 90% of TRLN’s CCC items viewed in the final six months of the project were from Duke. Its images averaged over 78 views apiece in the past year; its eighteen folders opened 363 times apiece. Why? The publication of this collection coincided with an on-campus exhibit. And it was incorporated into multiple courses at Duke for assignments to write using primary sources.
The takeaway is, sometimes having interesting, important, and timely content available for use online is more important than the features enabled or the process by which it all gets there.
Looking Ahead
We’ll keep pushing ahead with evolving our practices for putting digitized materials online. We’ve introduced many recent enhancements, like fulltext searching, a document viewer, and embedded HTML5 video. Inspired by the CCC project, we’ll continue to enhance our finding aids to provide access to digitized objects inline for context (e.g., The Jazz Loft Project Records). Our TRLN partners have also made excellent upgrades to the interfaces to their CCC collections (e.g., at UNC, at NC State) and we plan, as usual, to learn from them as we go.
A unified search results page, commonly referred to as the “Bento Box” approach, has been an increasingly popular method to display search results on library websites. This method helps users gain quick access to a limited result set across a variety of information scopes while providing links to the various silos for the full results. NCSU’s QuickSearch implementation has been in place since 2005 and has been extremely influential on the approach taken by other institutions.
Way back in December of 2012, the DUL began investigating and planning for implementing a Bento search results layout on our website. Extensive testing revealed that users favor searching from a single box — as is their typical experience conducting web searches via Google and the like. Like many libraries, we’ve been using Summon as a unified discovery layer for articles, books, and other resources for a few years, providing an ‘All’ tab on our homepage as the entry point. Summon aggregates these various sources into a common index, presented in a single stream on search results pages. Our users often find this presentation overwhelming or confusing and prefer other search tools. As such, we’ve demoted the our ‘All’ search on our homepage — although users can set it as the default thanks to the very slick Default Scope search tool built by Sean Aery (with inspiration from the University of Notre Dame’s Hesburgh Libraries website):
The library’s Web Experience Team (WebX) proposed the Bento project in September of 2013. Some justifications for the proposal were as follows:
Bento boxing helps solve these problems:
We won’t have to choose which silo should be our default search scope (in our homepage or masthead)
Synthesizing relevance ranking across very different resources is extremely challenging, e.g., articles get in the way of books if you’re just looking for books (and vice-versa).
We need to move from “full collection discovery to full library discovery” – in the same search, users discover expertise, guides/experts, other library provisions alongside items from the collections. 1
“A single search box communicates confidence to users that our search tools can meet their information needs from a single point of entry.” 2
Sean also developed this mockup of what Bento results could look like on our website and we’ve been using it as the model for our project going forward:
For the past month our Bento project team has been actively developing our own implementation. We have had the great luxury of building upon work that was already done by brilliant developers at our sister institutions (NCSU and UNC) — and particular thanks goes out to Tim Shearer at UNC Libraries who provided us with the code that they are using on their Bento results page, which in turn was heavily influenced by the work done at NCSU Libraries.
Our approach includes using results from Summon, Endeca, Springshare, and Google. We’re building this as a Drupal module which will make it easy to integrate into our site. We’re also hosting the code on GitHub so others can gain from what we’ve learned — and to help make our future enhancements to the module even easier to implement.
Our plan is to roll out Bento search in August, so stay tuned for the official launch announcement!
PS — as the 4th of July holiday is right around the corner, here are some interesting items from our digital collections related to independence day: