

About four years ago we released a small Ruby gem (EDTF-Humanize) to generate human readable dates out of Extended Date Time Format dates. For some background on our use of the EDTF standard, please see our previous blog posts on the topic: EDTF-Humanize, Enjoy your Metadata: Fun with Date Encoding, and It’s Date Night Here at Digital Projects and Production Services.
Some recent community contributions to the gem as well as some extra time as we transition from one work cycle to another provided an opportunity for maintenance and refinement of EDTF-Humanize. The primary improvement is better support for languages other than English via Ruby I18n locale configuration files and a language specific module override pattern. Support for French is now included and support for other languages may be added following the same approach as French.
The primary means of adding additional languages to EDTF-Humanize is to add a translation file to config/locals/. This is the translation file included to support French:
fr:
date:
day_names: [Dimanche, Lundi, Mardi, Mercredi, Jeudi, Vendredi, Samedi]
abbr_day_names: [Dim, Lun, Mar, Mer, Jeu, Ven, Sam]
# Don't forget the nil at the beginning; there's no such thing as a 0th month
month_names: [~, Janvier, Février, Mars, Avril, Mai, Juin, Juillet, Août, Septembre, Octobre, Novembre, Decembre]
abbr_month_names: [~, Jan, Fev, Mar, Avr, Mai, Jun, Jul, Aou, Sep, Oct, Nov, Dec]
seasons:
spring: "printemps"
summer: "été"
autumn: "automne"
winter: "hiver"
edtf:
terms:
approximate_date_prefix_day: ""
approximate_date_prefix_month: ""
approximate_date_prefix_year: ""
approximate_date_suffix_day: " environ"
approximate_date_suffix_month: " environ"
approximate_date_suffix_year: " environ"
decade_prefix: "Les années "
decade_suffix: ""
century_suffix: ""
interval_prefix_day: "Du "
interval_prefix_month: "De "
interval_prefix_year: "De "
interval_connector_approximate: " à "
interval_connector_open: " à "
interval_connector_day: " au "
interval_connector_month: " à "
interval_connector_year: " à "
interval_unspecified_suffix: "s"
open_start_interval_with_day: "Jusqu'au %{date}"
open_start_interval_with_month: "Jusqu'en %{date}"
open_start_interval_with_year: "Jusqu'en %{date}"
open_end_interval_with_day: "Depuis le %{date}"
open_end_interval_with_month: "Depuis %{date}"
open_end_interval_with_year: "Depuis %{date}"
set_dates_connector_exclusive: ", "
set_dates_connector_inclusive: ", "
set_earlier_prefix_exclusive: 'Le ou avant '
set_earlier_prefix_inclusive: 'Le et avant '
set_last_date_connector_exclusive: " ou "
set_last_date_connector_inclusive: " et "
set_later_prefix_exclusive: 'Le ou après '
set_later_prefix_inclusive: 'Le et après '
set_two_dates_connector_exclusive: " ou "
set_two_dates_connector_inclusive: " et "
uncertain_date_suffix: "?"
unknown: 'Inconnue'
unspecified_digit_substitute: "x"
formats:
day_precision_strftime_format: "%-d %B %Y"
month_precision_strftime_format: "%B %Y"
year_precision_strftime_format: "%Y"
In addition to the translation file, the methods used to construct the human readable string for each EDTF date object type may be completely overridden for a language if needed. For instance, when the date object is an instance of EDTF::Century the French language uses a different method from the default to construct the humanized form. This override is accomplished by adding a language module for the French language that includes the Default module and also includes a Century module that overrides the default behavior. The override is here (minus the internals of the humanizer method) as an example:
# lib/edtf/humanize/language/french.rb
module Edtf
module Humanize
module Language
module French
include Default
module Century
extend self
def humanizer(date)
# Special French handling for EDTF::Century
end
end
end
end
end
end
EDTF-Humanize version 2.0.0 is available on rubygems.org and on GitHub. Documentation is available on GitHub. Pull requests are welcome; I’m especially interested in contributions to add support for languages in addition to English and French.





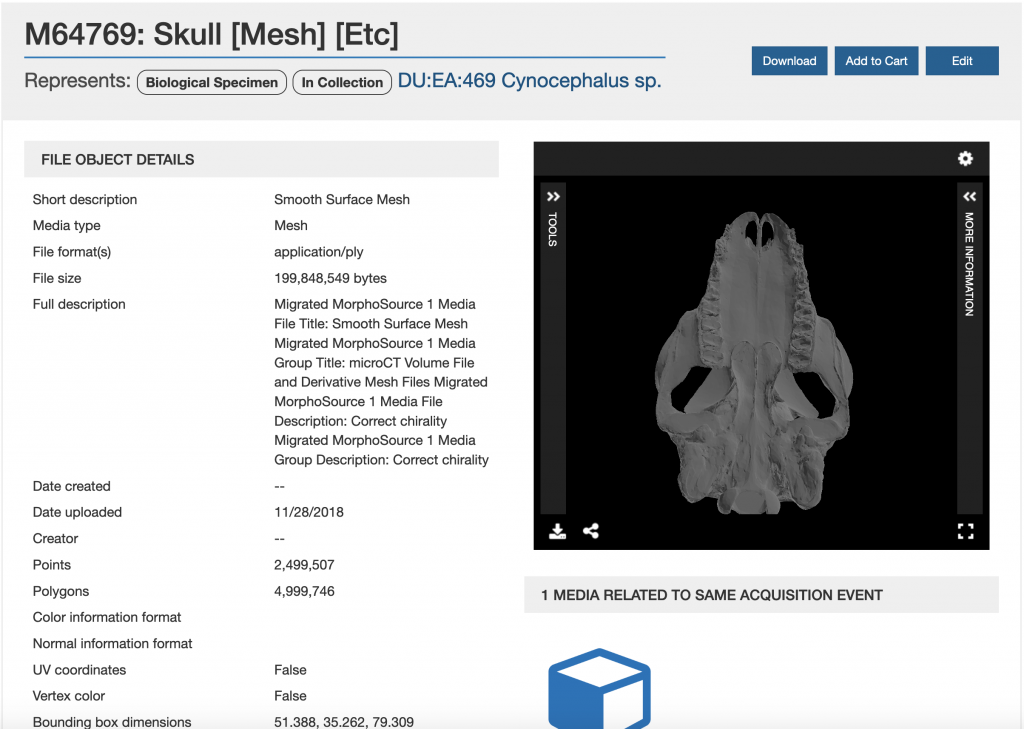
 Header Image: Collection of extinct and extant turtle skull microCT scans in MorphoSource:
Header Image: Collection of extinct and extant turtle skull microCT scans in MorphoSource: 









 Once the shot is in focus and appropriately bright, we will check our colors against an X-Rite ColorChecker Classic card (see the photo on the left) to verify that our camera has a correct white balance.
Once the shot is in focus and appropriately bright, we will check our colors against an X-Rite ColorChecker Classic card (see the photo on the left) to verify that our camera has a correct white balance. 

