This room is the student’s workshop.
This is the Socratean basket in which he is lifted from the business world. Professor William Francis Gill (T 1894), on libraries.
The Gill Endowment
The single endowment for collections in Classical Studies for the Duke University Libraries was created in memory of Latin Professor William “Billy” Francis Gill in December 1917. Native to Henderson, North Carolina, Professor Gill graduated from Trinity College in 1894, and completed his graduate work at Johns Hopkins University in 1898. He returned to Trinity to teach until his untimely death in October of 1917. He established Duke’s Classical Club in 1910. Materials in the Duke University Archives, and Johns Hopkins University Archives, offer glimpses of the life, personality, and scholarship of Professor Gill, in a separate blog post: Professor of Latin, William Francis Gill (T 1894) .
Lilly’s Loeb Classics Collection
Greek Loeb Classics on the Move
The Loeb Classics are facing editions in Latin and Greek, with 560 volumes in a complete set. Over the last 100 years, Duke University Libraries have collected duplicate, triplicate and in some cases five or six copies of each author, with several thousand copies currently in the University’s Libraries. Lilly’s Loebs duplicate two complete collections in Perkins Library, many editions in the Divinity School Library, as well as the online Loeb Classical Library. There is another collection at Duke’s Kunshan Library.
As the original library of Trinity College, Lilly’s collection includes some of the oldest acquisitions, many of them bought for the Woman’s College Library in the 1930s. Many are in good condition, others are visibly tattered, worn, loved, and annotated by generations of students who studied Latin and Greek on East Campus.
In the spirit of Professor Billy Gill’s commitment to classical scholarship and teaching, in preparation of Lilly’s renovation, and in honor of those studious alumni, we are giving away the Lilly Loebs as gifts to Duke’s current students, faculty and staff. Each book includes a plate commemorating the Lilly Renovation Project, designed by Ms. Carol Terry, of Lilly Library.
Duke faculty, staff and students are invited to select gift copies from the Lilly Library Loeb Classics collection. Details:
Lilly Gives its Loebs to Duke Students, Faculty, and Staff
Guest post by Gabe Cooper, a first-year student from Columbia, SC. He intends to major in Economics with maybe a French minor and an Innovation & Entrepreneurship Certificate.
A dynamic scene of a caiman holding a false coral snake in its mouth, from Maria Sibylla Merian’s Surinam Album.
I discovered this FOCUS cluster almost completely by accident. I came up to Duke to visit during Blue Devil Days and chose to attend a lecture about unraveling the secrets of Leonardo da Vinci, knowing I had enjoyed learning about the Renaissance in the past but also not really knowing what I was getting myself into. When I walked into the lecture room, I was greeted by an eccentric, wise person; the epitome of a college history professor—this is when I met Professor Robisheaux.
Gabe Cooper
I was expecting the mini lecture to be simple—a lecture where Professor Robisheaux talked to us about Leonardo da Vinci. Instead, he tasked the class of newly accepted Duke students to unravel the mystery of Leonardo ourselves. How was the world connected for Leonardo da Vinci? What did his artwork, architectural designs, and a piece of music have in common? All these questions Professor Robisheaux asked us, and all that we had to answer were primary materials and each other. Suddenly, I was in the position to be the one who investigated and be the historian; Professor Robisheaux was just a guide.
This experience during Blue Devil Days drew me to sign up for this MedRen FOCUS cluster because Professor Robisheaux’s teaching style was unlike anything I had ever experienced before, and the lecture made me rethink everything I knew about Leonardo da Vinci and the Renaissance. I wanted to explore this cluster further, and I am so glad I did.
As a student interested in the sciences, what did studying the Renaissance in a humanities program like the MedRen Focus teach you?
The MedRen FOCUS taught me that the distinctions we make today between different subjects in the sciences and the humanities are not as strong as I previously believed. Almost all the figures we studied with Professor Robisheaux were polymaths: Leonardo da Vinci was an artist, scientist, engineer, and courtier; Maria Sibylla Merian was an artist, biologist, and explorer; Paracelsus was a physician who understood medicine and the human body through art and his religious beliefs. Everything was interconnected during the Renaissance, and by studying this period in history, I’ve been better able to see the interconnectedness of the world around me.
A busy scene of Huntsman spiders, pink toe tarantulas, leaf-cutter ants, and a ruby-topaz hummingbird, from Maria Sibylla Merian’s Insects of Suriname.
What was it like encountering early printed books from the Renaissance for the first time?
It was stupefying to encounter early printed books because time seemed to have collapsed. These books were a physical representation of time—they had survived centuries before me and would likely survive centuries after me. But at the same time, the books were just books. They looked ordinary and you could still understand their pictures and sometimes even what they were saying. It was a weird dichotomy between awe and ordinariness, and I would highly encourage anyone to explore the Rubenstein Library’s collection.
What was your topic for the final paper in Professor Robisheaux’s class? What did you choose to write about and why?
My topic for my final paper in Professor Robisheaux’s class was centered around the question “How did art become the pinnacle of subjectivity that we know today?” I came up with this question because throughout Professor Robisheaux’s course, a key theme that emerged in our discussions was the fact that art was viewed as mainly objective during the Renaissance, with very set guidelines and procedures. However, while looking at De europische insecten at the Rubenstein Library during class one day, Maria Sibylla Merian seemed to stand out as an outlier. All of her work had very little commentary, a sense of chaos, and focused on the subjective, individual experience of nature.
And perhaps the most exemplary in accomplishing this switch to subjectivity is Merian’s Surinam Album, which masterfully displaying the wildlife of Surinam in the eighteenth century. This album, full of vibrant colors, intricate details, and dynamic scenes, gives the impression that Merian is tasking the viewer with making sense of what these scenes in nature mean, as if she is rendering them the scientist. I wanted to dive deeper into these themes in my final paper, using everything I had learned throughout the course to try to become a historian.
Two Menelaus Blue Morpho butterflies fluttering around its caterpillar form on a Barbados Cherry, from Maria Sibylla Merian’s Insects of Suriname.
Any other things you would like others (especially future students!) to know about the FOCUS program or the Libraries?
One of the most valuable aspects of FOCUS is the relationships you make with fellow classmates and your professors. Meeting with Professor Robisheaux, Professor Kate Driscoll, Professor Roseen Giles, Dr. Heidi Madden, Ms. Rachel Ingold, and all of your classmates every week for dinner and field trips allows you to really get to know everyone in your FOCUS program. This is truly invaluable because when you take FOCUS as a first semester freshman, you are dealing with a lot of uncertainty. Who will be your friends? Are you going to achieve the same amount of success you did in high school? How do you deal with being on your own? Having a tightly-knit community that is provided by FOCUS makes the entire college transition much easier because you have professors and librarians that want to help you succeed and classmates who are going through the same challenges you are.
This blog post was co-authored by Alaina Economus, Slavic Language Resource Description Intern, Resource Description Department, and Erik Zitser, Librarian for Slavic, Eurasian, and East European Studies atDuke University Libraries.
Is it true that Duke University Libraries hold the largest collection of Ukrainian language materials in in the southeastern United States? How do we know? And why does it matter? These are the questions that guided the collection analysis project that Alaina Economus undertook in the summer of 2023 as part of the Field Experience course for the Master of Science in Library Science degree at the University of North Carolina-Chapel Hill (UNC-CH), under the supervision of Erik Zitser, Librarian for Slavic, Eurasian, and East European Studies at Duke University Libraries (DUL).
Why Knowing About Duke’s Ukrainian Language Collection Matters
Although DUL has been collecting Ukrainian language publications since before Ukraine’s formal declaration of independence from the Union of Soviet Socialist Republics (USSR) in 1991, until now this research collection has not received a formal quantitative assessment. According to the existing library literature, doing a collection analysis is an important way of determining not only the size and focus of a particular academic collection, but also the extent to which it fulfills the research and teaching mission of both the university and the broader scholarly community. Unfortunately, relying on circulation statistics—the standard way of determining the “fit” between a collection and its users—is not very effective in the case of non-English (“foreign”) language materials. That is because such research materials support a relatively small, but select audience of specialists and, consequently, do not circulate as frequently as works published in the dominant language of most of the people who use the scholarly resources collected by American research libraries.
That is why, after conducting a literature review on the topic of collection assessment in general and Slavic language collections in particular, Alaina decided to focus not on the circulation of Duke’s Ukrainian language materials—whether among members of the Duke University community or between DUL and its interlibrary loan partners in the Triangle Research Library Network (TRLN) and Ivy Plus Libraries Confederation—but on the internal coherence of DUL’s Ukrainian collection as a whole, i.e., the extent to which these primary and secondary sources represent an interdisciplinary field of study (rather than one specific topic or area of focus) that can support at least the initial phase of a scholarly research project. For example, researchers specializing in contemporary Ukrainian literature must have access to a diverse range of works and authors. Additionally, they require a language-specific bibliographic index that includes journals not covered by English-language databases such as the MLA International Bibliography. Full-text access to major Ukrainian journals, as well as reference works and materials on authors, historical events, and cultural context (including works in English), are also necessary for the coherency and currency of this non-English-language circulating collection.
An analysis of the Ukrainian language collection at DUL is not only useful, but also topical, especially within the context of Russia’s ongoing, neo-imperialist war against Ukraine. Assessing DUL’s collection of Ukrainian language materials at a moment when Ukrainian cultural institutions (including libraries) are under direct military attack, gives Alaina’s project an added political dimension. From this perspective, this collection assessment project can be seen not only as a contribution to the decolonization of the (Russocentric) field of Slavic area studies but also to a broader dialogue about the importance of non-English language-specific materials in promoting bibliodiversity and supporting the cultural preservation of, and access to “at-risk” library collections.
The Current Composition of Duke’s Ukrainian Language Collection
A quantitative analysis of DUL’s Ukrainian language collection confirms that DUL does, indeed, hold the largest collection of Ukrainian language materials in the southeastern United States. Just as importantly, it also documents the effectiveness of the Slavic language cooperative collection development agreement between DUL and UNC-CH libraries, the two main institutions primarily responsible for collecting Slavic language materials in the Research Triangle.
At the time of data collection (July 2023), Duke University Libraries held 11,744 Ukrainian-language items. As Figure 1 demonstrates, the majority of these items were monographic (87%) and serial (12%) publications, with only a smattering of Ukrainian-language audiovisual and cartographic materials.
Figure 1: Formats
As of July 2023, roughly 6% of the collection had not received any Library of Congress call number or subject heading analysis, and approximately 12% were assigned either an obsolete (Dewey Decimal) call number, government document identification number, or another classification identification. In other words, almost 20% of the Ukrainian collection remained un- or under-cataloged. Consequently, the following description relates primarily to the remaining 80% of the collection (approximately 9,400 items).
As one would expect in a general research collection focused primarily on humanities and social sciences, an analysis of LC-subject headings (Figure 2) reveals that the DUL’s Ukrainian collection is lacking in materials related to science, medicine, technology, and music; however, except for literature, history, and social sciences, no other subject class makes up more than 5% of the overall collection.
Figure 2: LC-Subject Class Analysis
Over half of the collection (56%) is comprised of items assigned P (Literature) or D (History) call numbers, a majority of which are PG (Slavic languages, Baltic languages, and Albanian languages) and DK (History of Russia, Soviet Union, and former Soviet Republics) call numbers, respectively. As Figure 3 demonstrates, breaking down the PG class further shows that contemporary Ukrainian literature represents almost half of the total items assigned P call numbers. Approximately 11% of such items is Ukrainian-language literature that has been published after 2001.
Figure 3: Ukrainian Literature by Call Number
The Benefits of Collaborative Collection Development
DUL’s Ukrainian-language holdings compare favorably to those of other members of the East Coast Consortium for Slavic Collections (ECC), a library organization that was established in 1993 to “coordinate the activities of Eurasian area studies library collections located in the eastern United States and Canada.” Besides Duke University, ECC includes representatives from twelve other repositories of large Slavic collections: Columbia University, Cornell University, Dartmouth College, Harvard University, Library of Congress, New York Public Library, New York University, Princeton University, University of North Carolina at Chapel Hill, University of Pennsylvania, University of Toronto, and Yale University. ECC members “work in concert with one another on the purchase of expensive resources…and cooperate on serial retention projects as well as duplicate exchange programs.” By means of “this type of coordination and cooperation each ECC member library can maximize its financial resources to meet the research, teaching and learning needs of their users.”
Figure 4: Ukrainian-language items at ECC Member Institutions. Source: OCLC WorldCat [*]
DUL’s contribution to this collective endeavor guarantees that students and scholars, both at Duke and nationwide, have access to “a full range of materials from and about this world area,” including from Ukraine. According to WorldCat data (which significantly undercounts the holdings in the library’s online public access catalog [*]), DUL has the eighth largest collection of Ukrainian-language materials in the ECC, with more materials than five other member libraries. Harvard University possesses the largest collection, with over 72,000 items. Dartmouth has the fewest with 286 items.
Since DUL and UNC-CH libraries are members both of ECC and TRLN, this quantitative analysis also sheds light on the effectiveness of the longstanding collection agreement between the Research Triangle’s two largest academic research libraries. Before the first decade of the 21st-century, primary responsibility for collecting research-quality Ukrainian language materials had belonged to DUL. Since 2010, however, DUL and UNC-CH have split the collecting responsibility between them: DUL now collects only Ukrainian-language materials published in the multi-national and multi-ethnic country that is post-independence Ukraine, while UNC-CH collects Ukrainian materials published in other languages, primarily Russian. As is the case with the ECC, such cooperation is intended to reduce duplication while increasing the number of unique items available in TRLN. By this logic, the number of shared items between the two institutions should be relatively low and should have declined in quantity since the mid-2000s. That is precisely what a quantitative analysis of duplicate Ukrainian titles between DUL and UNC demonstrates.
Figure 5: Duplicate Ukrainian Holdings: Duke and UNC, 2004-2023
According to Figure 5, from 2004 (the year DUL began to track items and functions via its current integrated library system) to 2022, there has been a significant decline in duplicate Ukrainian items held by both DUL and UNC-CH. While the decline began before the formal establishment of the present cooperative collection development agreement in 2010, the collaboration between the two institutions has succeeded in keeping duplicates down significantly (in the single digits) since 2015. This data speaks to the effectiveness of cooperation between DUL and UNC-CH in Ukrainian collecting, both to reduce costs for individual TRLN libraries, and to create a sound foundation for North Carolina-based students and scholars interested in conducting research on this region of the world.
The Distinctiveness of Duke’s Ukrainian Language Collection
One way of demonstrating the distinctiveness of the Ukrainian-language collection at DUL is to analyze its unique holdings. According to WorldCat, DUL possesses 73 unique Ukrainian-language items, and over a thousand items that are held by only two or three other libraries worldwide. These items represent a wide variety of formats, subject areas, and publication years. Of these items, we have selected two that showcase the uniqueness and breadth of DUL’s Ukrainian-language collection.
DUL is one of only four libraries in the world (and one of only two in North America) that hold any issues of Dnipro (“The Dnepr [River]”), a Ukrainian-language newspaper published in the United States by the Ukrainian Orthodox Church between 1921 and 1950. DUL holds seven unique runs of this historical newspaper for the period 1924 to 1942. These issues provide a glimpse into the world of the Ukrainian diaspora in the United States, as well as capture the reactions and emotions of Ukrainian-Americans regarding events occurring in Ukraine itself. One example is the paper’s coverage of the man-made famine (Ukr. Holodomor, “death by hunger”) that killed millions of ethnic Ukrainians during the Soviet campaign to “collectivize” agriculture in 1932 and 1933, under the dictatorship of Joseph Stalin. Throughout the early to mid-1930s, the paper reported extensively about the famine and related events, publishing written protests against the Soviet regime, appeals for donations to aid famine victims, and poetry from readers processing the horror at what they were reading in the paper.
Figure 6: Two issues of Dnipro(1932) from DUL’s American Newspaper Repository Collection
Dnipro contains important evidence not only the day-to-day life of the Ukrainian diaspora in the United States, but also captures the ways in which this community maintained and celebrated their culture abroad amidst persecution and repression at home. Its coverage, thus, complements that of the three other Ukrainian diaspora newspapers in DUL’s American Newspaper Repository Collection, which holds many foreign language and immigrant papers, including those produced by immigrants and expatriates from twentieth-century Russia and Eastern Europe. As is the case with Dnipro, some of these newspaper runs apparently exist nowhere else in the original (paper) format, which makes this collection of American historical newspapers of the Russian and East European diasporas into a resource of major scholarly significance.
DUL is also the only library in the United States to have a copy of Oderzhyma svobodoiu: shliakh Heroïni Svitu Iryny Senyk, a 2017 collection of poems, correspondence, writings, and needlework patterns of Iryna Senyk (1926-2009), a nurse, poet, and Soviet political dissident who was a member of both the Organization of Ukrainian Nationalists and the Ukrainian Helsinki Group. Senyk was imprisoned for a nonconsecutive total of 34 years spanning from 1945 to 1983 for her persistent support of Ukrainian sovereignty, her outspoken advocacy for other Ukrainian prisoners, and her work to bring international awareness to the human rights violations perpetrated by the Soviet regime. This book, which was published by Discursus, a small publishing house in the western Ukrainian village of Brusturiv (Kosivs’kyi raion, Ivano-Frankivs’ka oblast’), places Senyk’s writings into a larger context of the fight for Ukrainian independence during the Soviet period and provides an important example of the role of women not only in the preservation and celebration of Ukrainian culture, but also in the international human rights movement. In this sense, this unique item from the library’s circulating collection complements the non-circulating collection of the David M. Rubenstein Rare Books & Special Collections Library’s Sally Bingham Center for Women’s History & Culture and Human Rights Archive, extending their existing holdings to materials on non-Western women activists.
Conclusion
The preceding summary of Alaina’s research into the composition of DUL’s Ukrainian language collection showcases the importance of language-specific collection analysis in preserving cultural heritage and fostering academic research. Her work not only provides valuable insights into the composition, strengths, and gaps of the collection, but also speaks to the importance of accurate metadata to collection analysis projects. The comparison of DUL’s collection, specifically with the Ukrainian holdings of the UNC-CH library and other members of the East Coast Consortium of Slavic Library Collections, speaks to the utility and effectiveness of interinstitutional collection agreements. Finally, the unique materials presented as examples of the distinctiveness of DUL’s Ukrainian-language collection attest to its historical and cultural significance and, consequently, to its immense research potential for both current and future scholars.
The collection analysis project summarized in this blog post provides one concrete, practical example of the steps that library professionals can take to make the cultural products of formerly colonized nations like Ukraine more visible in American research repositories. The data collected during this study will be used to inform future decision about the DUL’s Ukrainian collection, including the kinds of materials we collect and the way these materials are described and made available to researchers.
For questions about the collection analysis project, please email alaina.economus@duke.edu. Inquiries about Duke’s Ukrainian collection more broadly can be addressed to ernest.zitser@duke.edu.
[*] The WoldCat data used to generate Figure 4 are only a rough approximation of actual institutional holdings and may significantly underrepresent the number of titles listed in each individual library’s open access online catalog (OPAC). For example, a search of the University of Toronto library’s OPAC demonstrates that this institution actually holds over 40,000 Ukrainian language titles (in all formats), nearly double the number listed in WorldCat. Thanks to Ksenya Kiebuzinski for this important clarification.
Duke Libraries’ resident aficionado of off-beat and oft-frightening films is back to cast a horror-ful look at houses both embodying and encasing evil. Enjoy this spine-tingling Lilly Library Collection Spotlight, curated every Halloween by Stephen Conrad, Team Lead of Monographic Acquisitions (and most importantly–movies), and enter his warped world of BAD HOUSES!
The Old Dark House – This pre-code chiller from director James Whale (‘Frankenstein’, ‘Invisible Man’ etc.) is a startling and also chuckling early-talkies take on the scary house theme. Five motorists seek shelter from a deluge in the titular Old Dark House, occupied by the cranky and bizarre Femm family. Boris Karloff gets his first top billing playing the servant Morgan, a brutish and hirsute drunk prone to rages. But beware, the biggest threat might be locked away upstairs…
The Innocents – Truman Capote co-wrote the screenplay for this 1961 adaptation of Henry James’s ‘Turn of the Screw’, directed by Jack Clayton. Deborah Kerr plays a young governess hired to take care of two young charges in a spooky and sprawling country estate. There is a haunting afoot though, with the house playing no small part in the mood and atmosphere. Brilliant cinematography by Freddie Francis really sets off the black & white scene, with truly effective use of candles and shadows.
The Sentinel– You’ll be gobsmacked by the stellar cast but then utterly horrified by the proceedings in this frightening 1977 evil house terror from Michael Winner. A young fashion model named Alison moves into a brownstone (at 10 Montague Place, in Brooklyn Heights, btw) also occupied by a blind priest. Soon after moving in things turn very strange and sinister for Alison, and her presence there is more intentional than expected, for “there is evil everywhere and the Sentinel is the only hope”.
House (Hausu) – For sheer, nightmarish, what-the-what-ness, there may not be a better movie than Nobuhiko Ôbayashi’s 1977 Hausu. A schoolgirl takes six of her classmates on a summer trip to her Aunt’s country house which is, yes, haunted. One by one they vanish, in an utterly brilliant, wacky and deranged series of happenings and scenarios. Some of the wildest and weirdest effects possible are employed, including hyper-wild uses of colors. Watch and discover that it is possible to view something slack-jawed while laughing and also being freaked out and thoroughly amazed.
House of the Devil– An early directorial effort from modern genre master Ti West, this 2009 throwback shocker is set in the ‘80s (complete with ample Walkman usage). A college student takes a strange babysitting gig at a large house on the outskirts of town on a lunar eclipse (tip: DON’T do that) and all hell breaks loose. The slow burn leads to a gruesome and graphic final chapter, making hash of whatever nerves you had left. Could it be…..Satan?
Do you recognize the movie that’s pictured at the top of this post? Test your trivia skills and see if you can Name that Film.
The Making of a Poet is a Trent Grant and Laertes Press sponsored residency for Mohsen Mohamed and Sherine Elbanhawy. In 2021, Mohsen published his first book of poetry, مفيش رقم بيرد (Mafīsh raqam bīrudd)which won first prize for vernacular poetry at the Cairo International Book Fair as well as the Sawiris Cultural Award. He wrote the poems while incarcerated in several prisons between 2014-2019 as he notes, “poetry in prison is like dreaming; it’s an alternative space to live, experience, and see the world.” Written in Egyptian Arabic, his poetry oscillates between longing and loss, between the present and the past, and between optimism and despair.
Mohsen will be joined by Sherine who was inspired to translate Mohsen’s work after a chance meeting at a workshop. She read his poetry and noted that “[his] poetry is very much ingrained in the tradition of poetry as a voice of resistance.” Sherine’s translation was published earlier this year by Laertes Press, an independent press committed to literary translation based in Chapel Hill and is entitled No One is On the Line.
The Bedfellows Are Sleeping and I’m Whispering
Oh, what a story,
the story
of my oppression
الرفاق نايمين و أنا بهمس
يا حكاية ظلمي يا حكاية
Mohsen was born in Mansoura, a city in Egypt located along the Nile, and had been pursuing a degree in Business Administration. However, he was wrongly arrested in 2014 and spent 5 years incarcerated in 6 different jails. He currently lives in Oxford, England. Last year he was interviewed about his poetry and his time in prison (in Arabic). Some of the poems in No One is On the Line, as well as new poems by Mohsen will be published later this year in a new collection of Egyptian prison writings in the post-2011 period by the University of California press.
In the deafening
silence of the nights
in the colossal
isolating barrier,
I grappled with question and answer,
like a mute who strives
to interrogate someone sightless
في الليالي وصمتها القاتل
والجدار العازل الحائل
كنت أجاوب فيها و أتسائل
زي أخرس يسأل الأعمي
حطوا ليه على عينه غماية
Sherine Elbanhawy, is currently pursuing a MA in Islamic Studies-Women and Gender Studies at McGill University. She holds an MFA in Creative Writing from the University of British Columbia. She’s the founder of Rowayat, a literary magazine showcasing Egyptian and Arab/SWANA writers.
Fawzi
Running and fleeing at a protest
in a snapshot caught by a friend,
a taste of teargas,
and people making way for you
to revive a friend
suddenly passed out.
On the left side
of the photo
betrayers and decent people.
In the back,
a throng, seen and unseen.
فوزي
وكر وفر في مظاهرة
و صورة لقطها ليك صاحبك
بطعم الغاز
وناس توسع لك طريق
علشان تداوي رفيق
أغمى عليه فجأة
وناس في شمال الصورة كات خاينة
وناس صادقة
وناس في الخلف مش باينة
وناس في الخلف
Over the course of the 23-27 Oct. week, Mohsen and Sherine will participate in a number of events and we hope you’ll attend!
On Tuesday, we’ll visit with Dr. Claudia Yaghoobi of the University of North Carolina at Chapel Hill for a reading and discussion with her students in her course entitled Iranian Prison Literature.
The next day, Mohsen and Sherine will present at the John Hope Franklin Centre as part of the W@C speaker series.
Knowledge
But I can still say
that I love, that I dream,
get inspired,
and get hurt.
The booming of the poem
vibrates inside iron bars,
but its wrists have never been shackled,
nor has steel ever muzzled its songs,
nor has the voice of an ode become hoarse.
المعرفة
لكني لسه بعرف أقول
وأحب وأحلم وانشرح
وانجرح
صوت القصيدة العالي يتسلل
بين الحديد أبو سلسلة ومعصم
الشعر عمره ف مرة ماتسلسل
ولا صوت غنا بحديد بتكمم
ولا عمر مرة قصيدة صوتها أتنبح
On Thursday evening, our esteemed guests will be hosted by Letters Bookshop in downtown Durham for a soirée of reading and translating. Sherine’s translation will be on sale and Mohsen and Sherine will be delighted to sign your copy!
Our final event, entitled Egypt’s carceral poetry and the public sphere will take place in Duke Libraries RL249 where Mohsen and Sherine will be in discussion with Duke University Professors Frances Hasso and Corina Stan. The hope is to extract commonalities and parallels that help us to understand the carceral experience with respect to care and caring, its reconfiguring of human distances, and its impact on human rights and the suppression of artists.
The Libraries provides access to thousands of streaming films to the Duke community, through multiple platforms. For Hispanic Heritage Month this year, take a look at our newest offering: PROJECTR. Projectr curates an ever-expanding collection of acclaimed movies, archival restorations, award-winning documentaries and artist-made works from around the world. Projectr offers over a hundred works exploring the Latinx and Latin American experience. You can browse this rich collection by Subject or Country, and get recommendations from independent filmmakers.
Here is a small selection that Projectr presents, with descriptions they provide. Explore and enjoy!
Fruits of Labor (dir. Emily Cohen Ibañez) A Mexican-American teenage farmworker dreams of graduating high school when ICE raids in her community threaten to separate her family and force her to become her family’s breadwinner. Fruits of Labor is a lyrical, coming-of-age documentary about adolescence, nature, and how ancestors paved the way for us.
La Flor (dir. Mariano Llinás) La Flor is an eight-part film, a decade in the making. It is an epic adventure in scale and imagination, a wildly entertaining ode to the power of storytelling. Filmed around the world, it is composed of six distinct episodes over eight parts, each starting the same four actresses. It redefines the concept of binge viewing.
An electrifying portrait of Brazil’s dystopian contemporary moment that blends documentary with narrative fiction and genre elements. “A politically incendiary ethnographic sci-fi…In Dry Ground Burning, the future isn’t just female: it is Black, lesbian, profoundly matriarchal.” —Sight and Sound
A River Below(dir. Mark Grieco) A captivating documentary about the ethics of activism in the modern media age. A River Below examines the efforts of two conservationists in the Amazon. One is a marine biologist and the other an animal activist and host of a popular National Geographic t.v. show. Their methods to save the pink river dolphin from extinction triggers unforeseen consequences.
Cuatro Paredes(dir. Matt Porterfield) A luminous short film by Matt Porterfield (SOLLERS POINT, PUTTY HILL) featuring rising star Barbara Lopez, CUATRO PAREDES follows Karla, recently arrived in Tijuana, Mexico to stay at her estranged aunt’s house a year after her father’s death. In this moment of solitude and calm, she looks up, down, inward and outward through the transpositional alchemy of text and is reminded that speaking to oneself feels like a vital human practice.
Are you curious about the history of Duke’s Engineering School? Would you like to hold an amputation saw from the 16th century as you contemplate the evolution of surgical tools? Do you want to know how a lipstick tester would work and how it came to Duke?
Join us for a special open house especially for students, faculty, and staff from the Pratt School of Engineering!
Date: Wednesday, September 27
Time: 12:00 – 3:00 p.m.
Location: Holsti-Anderson Family Assembly Room (Rubenstein Library 153)
Artifacts on display will highlight:
University Archives materials
medical instruments
other artifacts that reflect technological changes
Attendees will have a chance to browse materials and talk with library staff about our collections. Plus enter a raffle to win fabulous library swag! Hope to see you there!
The 5 Titles series highlights books, music, and films in the library’s collection, featuring topics related to diversity, equity, and inclusion and/or highlighting authors’ work from diverse backgrounds. Each post is intended to briefly sample titles rather than provide a comprehensive topic overview. Heather Martin, Librarian for African and African American Studies, selected this month’s 5 Titles. With its establishment as a federal holiday in 2021, Juneteenth/Freedom Day (June 19) gained wider national and international attention. Juneteenth celebrations originated in Texas to commemorate the arrival of Union Troops in Galveston on June 19, 1865 (two years after the Emancipation Proclamation) and the army’s announcement that all the enslaved people in Texas were free. However, emancipation celebrations by people of African descent have a long and varied history, marking multiple emancipation milestones (e.g., the British abolition of slavery, August 1, 1834; enactment of the Emancipation Proclamation, January 1, 1863; and the signing of the Thirteenth Amendment, February 1, 1865). This month’s five titles explore the history and representation of emancipation celebrations and their importance to the African American community, identity formation, and struggle for equality.
Rites of August First: Emancipation Day in the Black Atlantic World by J.R. Kerr-Ritchie. Kerr-Ritchie examines how August 1, 1834, the day that the British Abolition of Slavery Bill took effect, was celebrated throughout the West Indies, Canada, Britain, and the northern and western United States. He documents how the emancipation commemorations (called West India Day, August First Day, or Emancipation Day) encouraged anti-slavery activism in the United States and promoted connections among people of African descent across nationalist boundaries. Kerr-Ritchie also describes the day’s importance to communities of Black loyalists in Britain, Canada and Black militias around the Atlantic. Listings of commemorations held by specific churches and public celebrations in specific northern cities allow readers to explore local connections to August First.
Festivals of Freedom: Memory and Meaning in African American Emancipation Celebrations, 1808-1915 by Mitch Kachun. In his interpretation of emancipation celebrations from “the abolition of the Atlantic Slave Trade in 1808 through the fiftieth anniversary of U.S. emancipation in 1915,” Kachun traces the themes of how African Americans used these commemorations to create “a collective history of African American people” and how the commemorations were centers of conflict and controversy. Providing a chronological narrative of emancipation celebrations, the book’s chapters cover Freedom Day commemorations by free Blacks in the Northeast after the United States abolished the Atlantic slave trade on January 1, 1808; regional socializing and organizing opportunities for people of African descent during celebrations of the British abolition of slavery in the West Indies on August 1, 1834; the expansion of emancipation celebrations into the southern United States after the Civil War; and differences between the political focus of freedom festivals in different areas of the United States.
O Freedom! Afro-American Emancipation Celebrations by William H. Wiggins, Jr. Wiggins takes us on a tour of emancipation celebrations that he visited in 1972 and 1973. Each town observes a different emancipation commemoration date: Rockdale, Texas – June 19; Allensville, Kentucky – August 1, Columbus, Georgia – January 1; and Philadelphia, Pennsylvania – February 1. Through his research and excerpts from interviews taped with participants in these celebrations, Wiggins uncovers the significance of these differing Emancipation Day dates. The book includes detailed descriptions of Emancipation Day traditions, including the performance of historical pageants/dramas, church services, picnics, barbecues, parades, athletic contests, and political organizing (e.g., voter registration drives). Images of memorabilia and photographs from emancipation celebrations complement Wiggins’s narration and the interviews.
Envisioning Emancipation: Black Americans and the End of Slavery by Deborah Willis and Barbara Krauthamer. From the introduction: “Envisioning Emancipation explores how black people’s enslavement, emancipation, and freedom were represented, documented, debated and asserted in a wide range of photographs from the 1850s through the 1930s.” Curating photographs drawn from archives, museums, and libraries, Willis and Krauthamer create a visual narrative of the use of photography by enslavers, Black abolitionists (including Harriet Tubman, Sojourner Truth, and Frederick Douglass), and the formerly enslaved. Photographs provide a record of Black people during the Civil War and African American self-fashioning after emancipation. Includes multiple photographs of Emancipation Day celebrations.
On Juneteenth by Annette Gordon-Reed. Gordon-Reed’s brief and engrossing memoir melds Texas Hollywood myths (cowboys, ranchers, oilmen) and multiracial history with her recollections of Conroe, Texas, her small hometown. Juneteenth celebrations originated in Texas, and Gordon-Reed shares the story of enslaved and free Blacks in the area when it was part of Mexico, a separate republic, and later, a part of the United States. She examines the legacy of the Juneteenth celebration as well as African Americans’ continuing struggle for equality in the state and country. From MIT Press, “Reworking the traditional “Alamo” framework, she powerfully demonstrates, among other things, that the slave- and race-based economy not only defined the fractious era of Texas independence but precipitated the Mexican-American War and, indeed, the Civil War itself. In its concision, eloquence, and clear presentation of history, On Juneteenth revises conventional renderings of Texas and national history.”
Looking for something new to read? Check out our New and Noteworthy, Current Literature and Overdrive collections for some good reads to enjoy! Here is a selection of books you will find in these collections!
The Rabbit Hutch by Tess Gunty. Blandine isn’t like the other residents of her building. An online obituary writer. A young mother with a dark secret. A woman waging a solo campaign against rodents — neighbors, separated only by the thin walls of a low-cost housing complex in the once bustling industrial center of Vacca Vale, Indiana. Welcome to the Rabbit Hutch. Ethereally beautiful and formidably intelligent, Blandine shares her apartment with three teenage boys she neither likes nor understands, all, like her, now aged out of the state foster care system that has repeatedly failed them, all searching for meaning in their lives. Set over one sweltering week in July and culminating in a bizarre act of violence that finally changes everything, The Rabbit Hutch is a savagely beautiful and bitingly funny snapshot of contemporary America, a gorgeous and provocative tale of loneliness and longing, entrapment and, ultimately, freedom. Learn more about this National Book Award Winner in The New York Times Book Review.
Yellowface by R.F. Kuang. Authors June Hayward and Athena Liu were supposed to be twin rising stars. But Athena’s a literary darling. June Hayward is literally nobody. So when June witnesses Athena’s death in a freak accident, she acts impulsively: she steals Athena’s just-finished masterpiece, an experimental novel about the unsung contributions of Chinese laborers during World War I. So what if June edits Athena’s novel and sends it to her agent as her work? Doesn’t this piece of history deserve to be told, whoever the teller is? That’s what June claims, and the New York Times bestseller list seems to agree. But June can’t escape Athena’s shadow, and emerging evidence threatens to bring June’s (stolen) success down around her. As June races to protect her secret, she discovers how far she will go to keep what she thinks she deserves. With its immersive first-person voice, Yellowface grapples with questions of diversity, racism, cultural appropriation, and the terrifying alienation of social media.
The Measure by Nikki Erlick. Eight ordinary people. One extraordinary choice. It seems like any other day. You wake up, pour a cup of coffee, and head out. But today, when you open your front door, a small wooden box is waiting for you. This box holds your fate inside: the answer to the exact number of years you will live. In an instant, the world is thrust into a collective frenzy. Where did these boxes come from? What do they mean? Is there truth to what they promise? As society comes together and pulls apart, everyone faces the same shocking choice: Do they wish to know how long they’ll live? And, if so, what will they do with that knowledge? The Measure charts the dawn of this new world through an unforgettable cast of characters whose decisions and fates interweave with one another. Enchanting and deeply uplifting, The Measure is a sweeping, ambitious, and invigorating story about family, friendship, hope, and destiny that encourages us to live life to the fullest. Read more in The New York Times Book Review. This intriguing novel was selected as this year’s reading for first-year students Duke Common Experience.
The Forgotten Girls: A Memoir of Friendship and Promise in Rural America by Monica Potts. Growing up gifted and working-class poor in the foothills of the Ozarks, Monica and Darci became fast friends. The girls bonded over a shared love of reading and learning, even as they navigated the challenges of their tumultuous family lives and declining town. Monica left Clinton for college and fulfilled her dreams, but Darci and many in their circle of friends did not. Years later, working as a journalist covering poverty, Potts discovered what she already intuitively knew about the women in Arkansas: Their life expectancy had dropped steeply—the sharpest such fall in a century. This decline has been attributed to “deaths of despair”—suicide, alcoholism, and drug overdoses—but Potts knew their causes were too complex to identify in a sociological study. In this narrative, Potts deftly pinpoints the choices that sent her and Darci on such different paths and then widens the lens to explain why those choices are so limited.Learn more in this All Things Considered NPR interview.
Clytemnestra by Costanza Casati. A stunning debut follows Clytemnestra, the ancient world’s most notorious villainess, and the events that forged her into the legendary queen. As for queens, they are either hated or forgotten. She already knows which option suits her best…You were born to a king, but you marry a tyrant. You stand by helplessly as he sacrifices your child to placate the gods. You watch him wage war on a foreign shore, and you comfort yourself with violent thoughts. Because this was not the first offense against you. This was not the life you ever deserved. And this will not be your undoing. Slowly, you plot. But when your husband returns triumphantly, you become a woman with a choice. Acceptance or vengeance, infamy follows both. So, you bide your time and force the gods’ hands into the game of retribution. A blazing novel set in Ancient Greece, this is a thrilling tale of power, prophecies, hatred, love, and an unforgettable Queen who fiercely dealt death to those who wronged her.
Looking for something new to read? Check out our New and Noteworthy, Current Literature, and Overdrive collections for some good reads to enjoy! Here is a selection of books you will find in these collections!
The Skin and Its Girl by Sarah Cypher. In a Pacific Northwest hospital far from the Rummani family’s ancestral home in Palestine, the heart of a stillborn baby begins to beat, and her skin turns vibrantly, permanently cobalt blue. On the same day, the Rummanis’ centuries-old soap factory in Nablus is destroyed in an air strike. The family matriarch and keeper of their lore, Aunt Nuha, believes that the blue girl embodies their sacred history, harkening back to when the Rummanis were among the wealthiest soap makers and their blue soap was a symbol of legendary love. Decades later, Betty returns to Aunt Nuha’s gravestone, faced with a difficult decision: Should she stay in the only country she’s ever known, or should she follow her heart and the woman she loves, perpetuating her family’s cycle of exile? Betty finds her answer in partially translated notebooks that reveal her aunt’s complex life and struggle with her sexuality, which Nuha hid to help the family immigrate to the United States. But, as Betty soon discovers, her aunt hid much more than that.
Birnam Wood by Eleanor Catton. A landslide has closed the Korowai Pass on New Zealand’s South Island, cutting off the town of Thorndike and leaving a sizable farm abandoned. The disaster presents an opportunity for Birnam Wood, an undeclared, unregulated, sometimes-criminal, sometimes-philanthropic guerrilla gardening collective that plants crops wherever no one will notice. For years, the group has struggled to break even. To occupy the farm at Thorndike would mean a shot at solvency at last. But the enigmatic American billionaire Robert Lemoine also has an interest in the place: he has snatched it up to build his end-times bunker, or so he tells Birnam’s founder, Mira, when he catches her on the property. A gripping psychological thriller from the Booker Prize–winning author of The Luminaries, Eleanor Catton’s Birnam Wood is Shakespearean in its drama, Austenian in its wit, and, like both influences, fascinated by what makes us who we are. Learn more about this novel in The New York Times Book Review.
The Trackers by Charles Frazier. Hurtling past the downtrodden communities of Depression-era America, painter Val Welch travels westward to the rural town of Dawes, Wyoming. Through a stroke of luck, he’s landed a New Deal assignment to create a mural representing the region for their new Post Office. A wealthy art lover named John Long and his wife Eve have agreed to host Val at their sprawling ranch. Rumors and intrigue surround the couple: Eve left behind an itinerant life riding the rails and singing in a Western swing band. Long holds shady political aspirations but was once a WWI sniper—and his right hand is a mysterious elder cowboy, a vestige of the violent old west. Val quickly finds himself entranced by their lives. One day, Eve flees home with a valuable painting in tow, and Long recruits Val to hit the road to track her down. American writer Charles Frazier conjures up the lives of everyday people during an extraordinary period of history that bears an uncanny resemblance to our own. Read The Washington Post book review to learn more!
The Only Survivors by Megan Miranda. A decade ago, two vans filled with high school seniors on a school service trip crashed into a Tennessee ravine—a tragedy that claimed the lives of multiple classmates and teachers. The nine students who managed to escape the river that night were irrevocably changed. A year later, after one of the survivors dies by suicide on the anniversary of the crash, the rest make a pact: to come together each year to commemorate that terrible night. Their annual meeting place, a house on the Outer Banks, has long been a refuge. But by the tenth anniversary, Cassidy Bent has worked to distance herself from the tragedy and the other survivors. This year, she is determined to finally break ties once and for all. But on the reunion day, she receives a text with an obituary attached: another survivor is gone. Now they are seven—and Cassidy finds herself hurling back toward the group, wild with grief—and suspicion. A propulsive and chilling locked-box mystery filled with the dazzling hairpin twists that are the author’s signature.
A Living Remedy by Nicole Chung. Nicole couldn’t hightail it out of her overwhelmingly white Oregon hometown fast enough. As a scholarship student at a private university on the East Coast, no longer the only Korean she knew, she found community and a path to the life she’d long wanted. But the middle-class world she begins to raise a family in – where there are big homes, college funds, and nice vacations – looks very different from the middle-class world she thought she grew up in. When her father dies at only sixty-seven, killed by diabetes and kidney disease, Nicole feels deep grief and rage, knowing that years of precarity and lack of access to healthcare contributed to his early death. Exploring the enduring strength of family bonds in the face of hardship and tragedy, A Living Remedy examines what it takes to reconcile the distance between one life, one home, and another – and sheds needed light on some of the most persistent and grievous inequalities in American society. Listen to Nicole discuss her work in this Fresh Air NPR interview!
A new exhibit in the IAS Office Exhibit Space, located on the second floor of Bostock library, showcases recent acquisitions on East Asia. New Chinese-language arrivals provide a glimpse of perspectives surrounding female agency and subjectivity during major political shifts in contemporary Chinese history. New Korean-language publications (including graphic novels) focus on important historical issues and events, such as the experience and testimony of Korean women during periods of Japan’s colonial occupation, and contemporary social and political movements in 20th-century Korea. Finally, our existing holdings in Japanese have been enhanced by a major gift of volumes focused on Japanese religion, which provides new research avenues for scholars of East Asian Buddhism.
Chinese Women’s Liberation Luo Zhou, Librarian for Chinese Studies
Duke University Libraries has expanded its collection with over 200 titles, primarily published during the 1950s and 1960s in the People’s Republic of China (PRC). These titles consist of original booklets and pamphlets that focus on women’s liberation and the promotion of the new Marriage Law, which was issued by the Chinese Communist Party (CCP) in 1950, only one year after the establishment of the PRC. The Marriage Law, which was the first fundamental law of the PRC, sought to provide a legal foundation for Chinese women to combat oppressive practices such as polygamy, widow chastity, child brides, and bride-wealth. The 1950 law was a significant legislative accomplishment for the CCP in terms of women’s liberation. The promotion of the new law was a nationwide effort, with numerous illustrated publications intended for women, 90% of whom were illiterate in the early 1950s. Concurrently, publications were issued to promote a new image of women as citizens capable of doing the same job, and seeking the same rights, as men. “Holding Up Half the Sky,” a slogan first introduced in the People’s Daily in the mid-1950s, best encapsulates the CCP’s goal of achieving two main social objectives: nurturing women’s individuality and their social productivity.
20th-Century Korean History Miree Ku, Librarian for Korean Studies
Duke’s Korean collection recently added new graphic novels (Korean manhwa), monographs, and biographies about important historical issues and events in 20th-century Korean history such as “comfort women, “the Korean War, and civil rights and pro-democracy movements.
Between 1932 and 1945, women from Japanese-occupied areas in Korea, China, and the Philippines were coerced or tricked into joining private military brothels. In some cases, women were kidnapped from their homes. Many of the new additions to Duke’s Korean collection focus on direct attestations of women, including oral interviews and letters, which provide a grim picture of violence against women during this period of Japanese colonial expansion. By preserving the physical record of East Asian female subjectivity, such accounts help researchers to understand not only the range of women’s experiences in colonial contexts, but also how direct testimony remains a valuable source of our historical knowledge. Additionally, the Libraries acquired several works covering contemporary democratic movements in Korea, especially the Gwangju Uprising (1980), which was a period of armed conflict between local citizens and South Korean military. Likewise, there are also new works on the June Democratic Struggle, which was a nationwide pro-democracy movement in South Korea that generated mass protests in the summer of 1987.
나비의 노래 (2014) https://find.library.duke.edu/catalog/DUKE006150494
풀: 살아 있는 역사, 일본군 위안군 할머니의 증언 (2017) https://find.library.duke.edu/catalog/DUKE008113730
Japanese Buddhism Matthew Hayes, Librarian for Japanese studies & Asian American studies
Finally, as part of a large-scale gift generously donated by Emeritus Professor of Buddhist Studies Paul Groner (UVA), Duke University Libraries received key works on Buddhism in East Asia. The work of Dr. Groner, who is a renowned scholar of Japanese Tendai Buddhism, has engaged disciplinary precepts and ordination, the status of nuns in medieval Japan, and later Buddhist educational systems in Japan. The first part of this two-part donation is comprehensive in scope, and includes biographical works focused on key Buddhist figures; expository and commentarial works focused on significant scriptures; philosophical works focused on concepts such as emptiness, non-self, the nature of the mind, and disciplinary ethics; as well as critical reference works. Duke’s current holdings tend toward contemporary Japanese Buddhist histories with a focus on the Zen sect. Dr. Groner’s donation thus fills a crucial chronological and sectarian gap in our current holdings and provides new and important resources for scholars working on East Asian Buddhist philosophy, philology, textual studies, commentarial traditions, law, or ritual. The second part of this donation will arrive in a few years, once Dr. Groner has completed the last of his projects, and will be of similar scale, but contain far more volumes in Japanese. Taken together, this gift will robustly support Buddhist Studies, and the study of East Asia more generally, among Duke faculty and students for decades to come.
APSI Spring Speaker Series talk by Dr. Groner; Image: Renate Kwon for APSI.
APSI launched its Spring Speaker Series by inviting Dr. Groner to give a talk, which was held at Duke Libraries on February 16th. He spoke about the nature of precept-taking in medieval Japanese Buddhism, after which attendees gathered to formally announce Dr. Groner’s donation to Duke Libraries. The exhibit showcasing these new arrivals to the East Asian Collection is on now through May 2023. Visitors to this exhibit space are encouraged to take a bibliographic guide to each title, located on the windowsill to the right of the exhibit case.
This post was contributed by Matthew Hayes, Librarian for Japanese Studies and Asian American Studies in the International and Area Studies Department of Duke University Libraries.
Duke University Libraries is pleased to announce the receipt of a large-scale gift from Emeritus Professor of Buddhist Studies Paul Groner. Dr. Groner received his PhD from Yale University, where he trained under Stanley Weinstein, and spent the majority of his career teaching at the University of Virginia. His research has largely focused on the Japanese Tendai school of Buddhism, which rose to prominence during the 10th century and encourages combinatory practice based on the Lotus Sutra, one of the preeminent scriptures in East Asian Buddhism. Dr. Groner has written prolifically even beyond this focus and has also conducted significant studies on disciplinary precepts and ordination, the status of nuns in medieval Japan, and later Buddhist educational systems in Japan. Dr. Groner’s donation to Duke Libraries reflects not only his rigor exercised across a career of scholarship, but also his ongoing support of the future of scholarship in Buddhist Studies and East Asian Studies.
Dr. Groner inaugurating the 2023 APSI Spring Speaker Series on February 16, 2023 with a talk on the observance of precepts in medieval Japanese Buddhism. Image: Renate Kwon for APSI.
Part I of Dr. Groner’s donation was physically received in March 2022 and consisted of nearly 1,200 English volumes, 600 Japanese volumes, and more than 100 Chinese volumes. Among the contents of this donation are biographical works focused on the lives and works of major figures across the Tendai, Zen, and Shingon schools of Japanese Buddhism, especially during the early medieval period. There are commentarial and expository works focused on concepts important to the study of East Asian Buddhism, such as emptiness, non-self, the nature of the mind, and disciplinary ethics. Likewise, while regional coverage of Dr. Groner’s donation is generally confined to East Asia, there are dozens of works related to religion in South and Southeast Asia. Part II of this donation will arrive in two years, once Dr. Groner has completed the last of his projects. This second portion will be similar in scale, though will contain far more Japanese volumes than in Part I and will focus more acutely on early medieval Japanese Tendai Buddhism.
From top: Saichō to Tendai no kokuhō: Tendaishū kaishū 1200-nen kinen 最澄と天台の国宝: 天台宗開宗: 一二〇〇記念, an exhibition catalog focused on images of Saichō, the founder of the Japanese Tendai tradition and focus of one of Dr. Groner’s major monographs, titled Saichō: The Establishment of the Japanese Tendai School (University of Hawai’i Press, 2000); Shōbōgenzō Eihei kōroku yōgo jiten「正法眼蔵」「永平広錄」用語辞典, a reference dictionary focused on key terms found in two seminal works by Sōtō Zen founder Dōgen; Sho, gaten sakuhinshū 書・画展作品集, an anthology of exhibit images showcasing religious calligraphy in various Asian languages. These and other selected items from Dr. Groner’s donation are currently on display in an exhibit on new arrivals to the East Asian Collection. The exhibit is located on the second floor of Bostock library, across from the International and Area Studies (IAS) suite. Images by author.
Taken together, both portions of this donation fill a significant chronological and sectarian gap in Duke’s current holdings and will help to elevate Duke Libraries as a major repository of East Asian Buddhist materials in the American Southeast. On behalf of Duke University Libraries, we look forward to future scholars benefitting from Dr. Groner’s generous bibliographic support of East Asian Buddhist Studies, and the study of East Asian religion more generally, for decades to come.
The Duke University Libraries are proud to present the 2023 Andrew T. Nadell Prize for Book Collecting. The contest is open to all students enrolled in an undergraduate or graduate/professional degree program at Duke, and the winners will receive cash prizes.
Winners of the contest will receive any in-print Grolier Club book of their choice, as well as a three-year membership in the Bibliographical Society of America.
You don’t have to be a “book collector” to enter the contest. Past collections have varied in interest areas and included a number of different types of materials. Collections are judged on adherence to a clearly defined unifying theme, not rarity or monetary value.
Visit our websitefor more information and read winning entries from past years. Contact Kurt Cumiskey at kurt.cumiskey@duke.edu with any questions.
Today, as inflation and economic uncertainty put severe stress on library collection budgets across North America, cooperative collection development is en vogue once again. Fortunately, librarians who collect for international and area studies have always been at the forefront of collaborative efforts to build robust and distinctive collections, even during tough economic times. One of the earliest and finest examples of such initiatives is the South Asia Acquisitions Program (SACAP), which this year celebrates its sixtieth anniversary.
The South Asia Cooperative Acquisitions Program (SACAP) was launched by the Library of Congress in 1962. This federal initiative was intended to foster the systematic and collaborative collecting of books, journals, and ephemera from this large, diverse, and multi-lingual region by research libraries right here in the United States. Recognising the importance of this field of study and the timeliness of this project, Duke University Libraries joined 10 peer institutions in agreeing to pay an annual fee of $500 USD—over $4,900 USD by today’s standards (according to the CPI Inflation Index)—in exchange for a selection of the latest South Asian publications. This collective investment in international collecting was an unparalleled success and SACAP continues to this day with Library of Congress field offices in New Delhi and Islamabad.
The materials on display in this 60th anniversary exhibition come from Duke University Libraries’ South Asia Pamphlet collection. Reputed to be the largest such collection in North America, it contains approximately 7,500 English-language pamphlets, with another 392 in Urdu and Bengali still waiting to be catalogued. The pamphlets cover a plethora of subjects: in addition to the items currently displayed in the Hubbard Case, there are pamphlets documenting tourism, economic development, arts, and refugees, among other topics. The collection comes from several South Asian countries: India, Afghanistan, Pakistan, Nepal, Sri Lanka, and Bangladesh.
Looking for something new to read? Check out our New and Noteworthy, Current Literature and Overdrive collections for some good reads to enjoy! Here is a selection of books you will find in these collections!
Our Missing Hearts by Celeste Ng. Twelve-year-old Bird Gardner lives a quiet existence with his loving but broken father, a former linguist who now shelves books in a university library. For a decade, their lives have been governed by laws written to preserve “American culture” in the wake of years of economic instability and violence. To keep the peace and restore prosperity, the authorities are now allowed to relocate children of dissidents, especially those of Asian origin, and libraries have been forced to remove books seen as unpatriotic—including the work of Bird’s mother, Margaret, a Chinese American poet who left the family when he was nine years old. Our Missing Hearts is an old story about how supposedly civilized communities can ignore the most searing injustice. It’s a story about the power—and limitations—of art to create change, the lessons and legacies we pass on to our children, and how any of us can survive a broken world with our hearts intact. Learn more here, The New York Times Book Review.
Demon Copperhead by Barbara Kingsolver. Set in the mountains of southern Appalachia, this is a story of a boy born to a teenage single mother in a single-wide trailer, with no assets beyond his dead father’s good looks and copper-colored hair, a caustic wit, and a fierce talent for survival. In a plot that never pauses for breath, relayed in his unsparing voice, he braves the modern perils of foster care, child labor, derelict schools, athletic success, addiction, disastrous loves, and crushing losses. Many generations ago, Charles Dickens wrote David Copperfield from his experience as a survivor of institutional poverty and its damage to children in his society. Those problems have yet to be solved in ours. In transposing a Victorian epic novel to the contemporary American South, Barbara Kingsolver enlists Dickens’ anger and compassion and, above all, his faith in the transformative powers of a good story. Read more in The Washington Post’s book review.
Acceptance by Emi Nietfeld. As a homeless teenager writing college essays in her rusty Toyota Corolla, Emi Nietfeld was convinced that the Ivy League was the only escape from her dysfunctional childhood. But upward mobility required crafting the perfect resilience narrative. She had to prove that she was an “overcomer,” made stronger by all she had endured. The truth was more complicated. Emi’s mom was a charming hoarder who had her put on antipsychotics but believed in her daughter’s brilliance—unlike the Minnesotan foster family who banned her “pornographic” art history flashcards (of Michelangelo’s David). Emi’s other parent vanished shortly after coming out as trans, a situation few understood in the mid-2000s. Both a chronicle of the American Dream and an indictment of it, this searing debut exposes the price of trading a troubled past for the promise of a bright future. Told with a ribbon of dark humor, Acceptance challenges our ideas of what it means to overcome. Read this NPR review to learn more.
Carry: A Memoir of Survival on Stolen Land by Toni Jensen. Jensen is a Métis woman, and she is no stranger to the violence enacted on Indigenous women’s bodies on Indigenous land. In Carry, Jensen maps her personal experience onto the historical, exploring how history is lived in the body and redefining the language used to speak about violence in America. In the title chapter, Jensen connects the trauma of school shootings with her experiences of racism and sexual assault on college campuses. “The Worry Line” explores the gun and gang violence in her neighborhood the year her daughter was born. “At the Workshop” focuses on her graduate school years, during which a workshop classmate repeatedly killed off thinly veiled versions of her in his stories. In prose at once forensic and deeply emotional, Toni Jensen shows herself to be a brave new voice and a fearless witness to her own difficult history–as well as to the violent cultural landscape in which she finds her coordinates. Read more about Jensen’s debut book here and an interview with Clemson University here.
Dog Flowers: A Memoir by Danielle Geller. A daughter returns home to the Navajo reservation to retrace her mother’s life in a memoir that is both a narrative and an archive of one family’s troubled history. When Geller’s mother dies of alcohol withdrawal while attempting to get sober, Geller returns to Florida and finds her mother’s life packed into eight suitcases. Most were filled with clothes, except for the last one, which contained diaries, photos, letters, a few undeveloped disposable cameras, dried sage, jewelry, and the bandana her mother wore on days she skipped a hair wash. Geller, an archivist and a writer uses these pieces of her mother’s life to try and understand her mother’s relationship to home and their shared need to leave it. Geller embarks on a journey that will end at her mother’s home: the Navajo reservation. Dog Flowers is an arresting, photo-lingual memoir that masterfully weaves together images and text to examine mothers and mothering, sisters and caretaking, and colonized bodies. Read more about this story in the Southern Review of Books.
For Native American History Month, one of Duke Libraries’ streaming video platforms, Docuseek, is highlighting a number of films about and made by Indigenous Peoples. Docuseek presents an excellent collection of documentary films about Native Americans, including National Film Board of Canada’s First Nations films, Women Make Movies, and distributors Bullfrog Films and Icarus Films.
These selections trace Indigenous activism, movement-building, politics, art, culture, language, astronomy, restorative-justice systems, and the fight to protect water and sacred lands.
As Nutayuneaan (dir. Anne Makepeace, 2011)
As Nutayuneaan (We Still Live Here)
Tells the amazing story of the return of the Wampanoag language, a language that was silenced for more than a century.
(Bullfrog Films; streaming with Duke netid/password)
Conscience Point (dir. Treva Wurmfeld, 2021)
Conscience Point Unearths a deep clash of values between the Shinnecock Indian Nation and their elite Hamptons neighbors, who have made sacred land their playground. (Women Make Movies; streaming with Duke netid/password)
Kanehsatake: 270 Years of Resistance (dir. Alanis Obomsawin, 2015)
Kanehsatake: 270 Years of Resistance
Examines the historic confrontation between the Mohawks, Québec police, and the Canadian army that propelled Native issues into the international spotlight and into the Canadian conscience.
(National Film Board of Canada; streaming with Duke netid/password)
The Mystery of Chaco Canyon, dir. Anna Sofaer, 2015)
The Mystery of Chaco Canyon
Unveils the ancient astronomy of southwestern Pueblo Indians.
(Bullfrog Films; streaming with Duke netid/password)
Skydancer (dir. Katja Esson, 2021)
Skydancer
Academy Award-nominated director Katja Esson explores the colorful and at times tragic history of the Mohawk skywalkers, men who leave their families on the reservation to travel to NYC to work construction jobs.
(Women Make Movies; streaming with Duke netid/password)
Standing on Sacred Ground (dir. Christopher McLeod, 2015)
Standing on Sacred Ground
In this four-part documentary series from the producer of In the Light of Reverence, native people share ecological wisdom and spiritual reverence while battling a utilitarian view of land in the form of government megaprojects, consumer culture, and resource extraction as well as competing religions and climate change.
(Bullfrog Films; streaming with Duke netid/password)
Native Cinema Showcase 2021
If these titles whet your appetite for more great movies, the Smithsonian’s National Museum of the American Indian’s Native Cinema Showcase is coming up later this month. An annual celebration of the best in Native film, this year’s showcase is online and runs from November 12-18, 2021. And Women Make Movies is screening online a selection of films by and about Native American women from November 19-30th; sign up here to receive more info.
In 1954, Frederic Wertham published the now infamous Seduction of the Innocent, linking juvenile delinquency to comics. Testifying before Congress in 1954, Wertham stated emphatically that “it is my opinion, without any reasonable doubt, and without any reservation, that comic books are an important contributing factor in many cases of juvenile delinquency.” The ensuing uproar on comics’ deleterious effects on the nation’s youth led to the creation of the Comics Magazine Association of American which in turn issued the Comics Code Authority (CCA).
While the adoption of the code by publishers was voluntary, comics without the CCA logo faced an uphill battle in terms of distribution. This de facto censorship system was wide-ranging, touching on such things as how persons in authority could be portrayed, how crimes could be presented, directives on illustrations, and the portrayals of marriage and sex.
The CCA had a long-term chilling effect on the portrayal of LGBTQIA+ characters in mainstream comics; However, its creation led to the vibrant underground comix movement where artists and authors ignored the strict code. Though the CCA was revised several times in the 1970s, loosening some restrictions, it wasn’t until 1992 in Alpha Flight #106 that Marvel’s Northstar stated, “I am gay.” The CCA was totally abandoned in the early 2000s.
Today, though there is still progress to be made, LGBTQIA+ persons and characters are found in graphic novels from superhero-themed to memoirs. The Lilly Graphic Novel Collection is a great place to begin your exploration. Below are a few highlights from our vast collection. Enjoy!
Fun Home
Fun Home by Alison Bechdel. In this award winning graphic memoir, Bechdel chronicles her relationship with her distant father, an English teacher and director of the town’s funeral home, “Fun Home” to the Bechdel family. From childhood through her coming out to her parents, Fun Home explores Bechdel’s fraught relationship with her father, the exploration of her sexuality, and a tragedy that leaves her much to reckon with. Fun Home was adapted for Broadway and has the distinction of being the first Broadway musical featuring a lesbian protagonist. It won the Tony award for Best Musical in 2015. Bechdel is also the author of the critically acclaimed Dykes to Watch Out For series.
Bingo Love
Bingo Love by Tee Franklin (author) and Jenn St.-Onge and Joy San (artists). In 1963, Hazel and Mari meet at church bingo, and their friendship grows into love. This new found love, however, is unacceptable to their families and their community, and Mari’s family moves away. Many years later, after Hazel and Mari each married and raised children, they reconnect at a bingo hall and realize that their feelings are unchanged. Fifty years later, through strength and determination, they claim the life that they always wanted. Bingo Love started as a Kickstarter project until it was picked up by Image Comics.
Our Work Is Everywhere
Our Work is Everywhere by Syan Rose. This graphic non-fiction work highlights the diverse voices in the queer and trans communities. Rose has a broad definition of work, not just what we do in our professional careers but also the ways that we improve ourselves, our communities, and our world. Interviews with queer and trans organizers, health justice activists, martial artists, and more are included, accompanied by Rose’s beautiful and expressive illustrations.
Gender Queer
Gender Queer by Maia Kobabe (author) and Phoebe Kobabe (colorist). Both a memoir and an introduction to eir family and readers on what it means to be non-binary, Kobabe (e/em/eir pronouns) chronicles eir journey of self-identity. Kobabe’s touching and honest story is a useful guide on gender identity for everyone.
Heartstopper
HeartstopperbyAlice Oseman. Begun as a serial webcomic in 2016, Heartstopper, available now in two printed volumes, introduces readers to Charlie and Nick who meet and develop a friendship at a British all-boys grammar school. The friendship grows into love. Optioned by Netflix, Heartstopper is slated for live-action adaptation in the near future.
These influential and impactful works are among the hundreds of titles in the Lilly Graphic Novel Collection, located in the first floor Carpenter Room.
The Duke University Libraries are proud to present the 2021 Andrew T. Nadell Prize for Book Collecting. The contest is open to all students enrolled in an undergraduate or graduate/professional degree program at Duke, and the winners will receive cash prizes.
Winners of the contest will receive any in-print Grolier Club book of their choice, as well as a three-year membership in the Bibliographical Society of America.
You don’t have to be a “book collector” to enter the contest. Past collections have varied in interest areas and included a number of different types of materials. Collections are judged on adherence to a clearly defined unifying theme, not rarity or monetary value.
Visit our websitefor more information and read winning entries from past years. Contact Kurt Cumiskey at kurt.cumiskey@duke.edu with any questions.
“Created in March 2020 at the onset of the pandemic — and curated by 29 librarians throughout the Ivy Plus Libraries Confederation and beyond — the Archive documents regional, social responses to the pandemic, which are critical in understanding the scope of the pandemic’s humanitarian, socioeconomic, and cultural impact. With an emphasis on websites produced by underrepresented ethnicities and stateless groups, the Archive covers (but is not limited to): sites published by non-governmental organizations that focus on public health, humanitarian relief, and education; sites published by established and amateur artists in any realm of cultural production; sites published by local news sources; sites published by civil society actors and representatives; and relevant blogs and social media pages. At the time of its launch, the Archive featured over 2,000 websites from over 80 countries in over 50 languages.”
This is the largest and most diverse Ivy Plus web archiving project ever created under the auspices of the thirteen-member library confederation. The Covid-19 web archive contains a multitude of materials—most of which are born digital—in all fields of research. The task of preserving such materialsis essential for future researchers. That is why the task has been assumed by the subject specialists of numerous research libraries, including here at Duke University. Four librarians from the International & Area Studies Department of Duke University Libraries are taking part in this digital initiative: Heather Martin, Miree Ku, Luo Zhou, and Sean Swanick. Each librarian also helped curate a subject guide hosted by Princeton University. The guide is divided by region and includes further information about the project and Ivy Plus Web Archiving.
Unfortunately, until the pandemic is over and some semblance of normalcy returns, this Ivy Plus web archiving project will continue to grow. If you have recommendations please send them along via this form.
Valentine Card. David M. Rubenstein Rare Book & Manuscript Library.
Surrounded by stories surreal and sublime, I fell in love in the library once upon a time. — Jimmy Buffett, “Love in the Library”
Maybe it’s the intimacy of hushed voices, the privacy of so many nooks and crannies, or the feeling of mysterious possibility that comes from being surrounded by so many books and stories. Let’s face it—there’s something romantic about libraries.
That’s why this Valentine’s Day has hit us right in the feels. Normally, in pre-pandemic times, we would be encouraging you right now to go on a “Mystery Date with a Book,” wrapping up dozens of our favorite titles in pink and red paper with come-hither teasers designed to lure you in.
Alas, our innocent fun is another casualty of COVID. But we’re still hoping we can spice up your reading life. We revisited our mystery picks from years gone by and pulled together some of our all-time favorite literary crushes, personally recommended by our staff. All titles are available to check out through our Library Takeout Service.
So go ahead, treat your pretty little self to something different. Who knows? You might just fall in love with a new favorite writer!
Selected by Arianne Hartsell-Gundy, Head, Humanities Section and Librarian for Literature and Theater Studies:
Arundhati Roy, The God of Small Things: “Seven year old twins are forever changed by one day in 1969.”
Naomi Novik, Uprooted: “The fairy tale you always wanted as a child…and finally got as an adult.”
Selected by Kim Duckett, Head of Research and Instructional Services:
Anthony Mara, The Tsar of Love and Techno: Stories: “A collection of beautiful interlocking short stories dipping back and forth through 20th century Russia.”
Matthew Kneale, English Passengers: “Twenty narrators tell a fascinating story of Manx smugglers, seekers of the Garden of Eden, and the plight of Tasmanian Aborigines.”
Selected by Brittany Wofford, Librarian for the Nicholas School for the Environment:
P. G. Wodehouse, How Right You Are, Jeeves: “For everyone who thought that Carson was the real hero of Downton Abbey.”
Selected by Megan Crain, Annual Giving Coordinator:
Gail Honeyman, Eleanor Oliphant is Completely Fine: “We all know what it means to survive. But do we know what it means to live in the 21st century?”
Madeleine L’Engle, A Wrinkle in Time: “A childhood classic about family, bravery, and finding light through the darkness.”
Selected by Aaron Welborn, Director of Communications:
Richard Hughes, The Innocent Voyage (A High Wind in Jamaica): “One of the best novels you’ve never heard of. A combination of Peter Pan, Heart of Darkness, and Lord of the Flies, all rolled into one.”
J. L. Carr, A Month in the Country: “A gem of a book: a quaint English village, a WWI vet, and a shimmering summer of youth.”
Selected by Elena Feinstein, Head, Natural Sciences and Engineering Section and Librarian for Biological Sciences:
Monique Truong, The Book of Salt: “Flavors, seas, sweat, tears – weaves historical figures into a witty, original tale spanning 1930s Paris and French-colonized Vietnam.”
Audrey Niffenegger, The Time Traveler’s Wife: “According to the author, the themes of the novel are ‘mutants, love, death, amputation, sex, and time.’ Many readers would include loss, romance, and free will.”
Selected by Jodi Psoter, Librarian for Chemistry and Statistical Science:
Selected by Ciara Healy, Librarian for Psychology & Neuroscience, Mathematics, and Physics
Carmen Maria Machado, In the Dream House: A Memoir: “If you lived through some stuff, and survived… this book is for you. Exquisitely written, heart wrenching.”
Edgar Cantero, Meddling Kids: “A Scooby Doo re-do; former kids detective club grows up, messes up and tries to solve a spooky mystery + actual dog as part of the Doo crew.”
Selected by Kelli Stephenson, Coordinator, Access and Library Services
Omar El Akkad, American War: “A second American Civil War, a devastating plague, and one family caught deep in the middle.”
Tamsyn Muir, Gideon the Ninth: “Necromancers unraveling a mystery in a haunted space mansion, complete with epic sword fighting, deep world-building, and laugh-out-loud profane humor.”
H2Omx – Best Documentary Feature Film (Mexican Academy of Cinematography 2015)
Docuseek, a streaming video platform of high quality documentary films, is showing its support for continuing education during the COVID-19 crisis by offering 12 films for free online streaming starting today through May 1. The theme of all 12 titles is sustainability centered around the 50th Anniversary of Earth Day and includes new films as well as popular classics.
The first documentary film to be screened is How to Let Go of the World and Love All the Things Climate Can’t Change by Josh Fox. Traveling to 12 countries on 6 continents, the film acknowledges that it may be too late to stop some of the worst consequences and asks, what is it that climate change can’t destroy? What is so deep within us that no calamity can take it away?
Come Hell or High Water: the Battle for Turkey Creek
Don’t worry if you miss a date, you will be able to access films released on previous days until May 1st. For more online viewing, check out the Duke Libraries’ streaming video* offerings of subscription and licensed films.
The True Cost – an investigation of “fast” fashion
*Note: access to these titles are limited to current Duke students, staff and faculty.
Animated April – Are you Team Pixar or Team Disney?
Brackets aren’t just for March!
Do you like Looney Tunes, the quirkiness of Wallace and Gromit, anime like Spirited Away, French comedies like The Triplets of Belleville? Are you all about Disney classics or the latest offerings from Pixar?
Lilly Library has 100s of animated films. In fact, we have so many animated films, it’s time for you to “toon” in and enjoy our very own Lilly Library Animated April challenge: Pixar versus Disney.
If it’s animated, Disney and Pixar are the dominant players, so we’re highlighting eight films from each studio to face off in a special edition of our Animated April challenge starting Monday, April 13th. Join in the fun, pick your favorites, and maybe win a prize!
Here’s how:
Vote when you visit our Lilly Library Animated April cast of characters HERE.
Make your selections and vote for your choice of hot titles in Bracket Fire versus films that landed in Bracket Earth to eventually face the coolest films in Bracket Ice, which challenge the animated gems making waves in Bracket Under the Sea.
All the Characters in Animated April
Voting dates are listed below and on the contest page.
Updates will be posted on Lilly’s Facebook, Instagram and Twitter accounts as well as in our blog, Latest@Lilly :
Round 4: Perfect Pair VOTE HERE Voting opens Monday, April 20 9am
Voting closes Tuesday, April 21 8pm
Champion Crowned: Wednesday April 22nd
*Did someone say PRIZES?
Participants who provide their Duke NetID and vote for the animated movie “champion” will be entered into drawings for virtual prizes, as well as special prizes for Duke students.
Be sure to make your picks of your favorites – Pixar or Disney!
Istanbul, also known as Der Saadet (Abode of Happiness), is a city unlike many others. Its very name evokes a mythical image of earthly paradise. And for those fortunate to have visited the Turkish cultural capital, whether for business (as I did during a book-buying trip) or pleasure, there are plenty of reasons why this is the case. Situated between the Black and Mediterranean seas, Istanbul has always been a picturesque city, brimming with diverse cultures, languages, ideas, and technologies. A collection of 174 Turkish postcards and photos from the late 1890s to the 1930s, recently digitized by Duke University Library, allows us to get a glimpse of this happy abode at the turn of the twentieth century, immediately before things went very badly.
Most of the images in the Istanbul postcards collection depict everyday life in Üsküdar, a historic neighborhood on the Asian side of Istanbul that was once home to thriving communities of Turks, Greeks, Armenians, Jews, and other ethnic groups. Considering Üsküdar’s cultural and linguistic diversity, it is not surprising that this neighborhood was also commonly known as Scutari (in English and Italian), likely a diminutive of the Greek Skoutàrion (Σκουτάριον), the original name of the area.
The Istanbul postcards collection contains striking images that document everyday life, historic buildings and ports, various architectural features, and other topics that may be of interest to students and researchers of late-nineteenth and early twentieth-century Istanbul.
Perhaps one of the more iconic landmarks in Istanbul is the Kız kulesi (Maiden’s Tower)–also known as Leander’s Tower (after the Greek myth of Hero and Leander)–a lighthouse situated in the Bosphorus straits, between the European and Asian sides of the city. There have been several towers over the centuries, with the original wood construction dating back to 1110 CE. The one depicted in this postcard was restored only in 1725. Here the Tower is festooned with lights to celebrate the ten-year anniversary since the founding of the Republic of Turkey (1923), a vivid example of the government’s attempt to appropriate historical sites of memory for contemporary political purposes.
On the banks of the Bosphorus lies the impressive Beylerbeyi Sarayı (Palace), the historic building depicted in the postcard below. Completed in 1865, the palace was the summer home of Sultan Abdülaziz (1830-1876), the first Ottoman Sultan to travel to Western Europe. After Greek nationalist forces defeated the Ottomans in Selanik in 1912, Sultan Abdülhamid (who had previously been confined to the Villa Allatini) would be forced to move to this palatial residence. The embossed stamp (reading “Constantinople,” rather than Istanbul) on the bottom left corner of the postcard suggests, however, that the creators of this souvenir sought to emphasize the building’s status as a European-style architectural landmark, rather than its role as a place of political exile.The influence of France, and in particular the French language, was pervasive throughout the Ottoman Empire in the nineteenth-century, especially among the literary elite. That is why, for example, many Ottoman-language journals (like the ones included in the recently launched digital project on the French Press in the Ottoman Empire), would often include a French translation or sub-title. To meet this growing demand, French educational entrepreneurs began opening schools in Istanbul. One of these schools, the Fransız Sainte Marie Okulu, is pictured in the postcard below. Note that although the writing on the back of the postcard is from 1933, the image of the school itself likely dates to the late nineteenth-century . Today, the historic building in which the school was once housed is part of a larger restoration project (Bağlarbaşı ilköğretim ve İş Okulu Restorasyonu).Another historic building depicted in the Turkish postcard collection is the Üsküdar Haydarpaşa Sultan tıbbiye mektebi (Üsküdar Haydarpaşa Sultan neighbourhood and Medical School). Built in 1827 as a military academy for the study of modern medicine, the school employed European and Ottoman doctors, who taught their students in French. The field of medicine was yet another example of the wide circulation of French (and, more broadly, European) ideas and practices in late Ottoman culture. You can learn more about the school and its place in Ottoman and European intellectual history with this recent publication.Another postcard on the theme of medicine and society is the one that portrays the Üsküdar miskinler tekkesi ve sebili (Üsküdar Leprosy house and water kiosk), the public health institution to which individuals suffering from this stigmatized infectious disease were confined and where they received such medical care as was available at the time. Although the term for this institution could also be translated as “lodges for the poor, helpless, wretched”—in addition to leper, the word miskinler, which is of Arabic origin with a Turkish suffix, also means poor, helpless, wretched; while tekke, a word borrowed from Persian but of Arabic origin, means lodge) —the miskinler tekkesi were colloquially known as tembelhâne, meaning “lazy houses.” Indeed, it is fair to say that rather than being sent for professional medical treatment, lepers were banished from society to live in miskinler tekkesi. For further information on Ottoman laws and debates about such matters see Studies in old Ottoman criminal law. And for further information about Ottoman disability studies, see Disability in the Ottoman Arab World, 1500-1800.A few images in the newly-digitized Istanbul postcard collection depict a very dark period of Turkish history, known as İşgal (the period of foreign occupation). After its defeat in World War I (1918), the Ottoman Empire was dismembered by the victorious military powers. As a direct result, British, French, Italian, and Greek troops moved into the former Abode of Happiness and took over the administration of the city. Istanbul and its residents were kept under strict watch, not least by means of naval vessels, such as the two steamships depicted, in the postcard below, patrolling the waters off Ortaköy with Üsküdar in the foreground. This tumultuous period witnessed the rise of Mustafa Kemal Ataturk and ended only with the founding of the Republic of Turkey in 1923 (a defining political event that was celebrated as a national holiday in the abovementioned postcard of the Maiden’s Tower, and that continues to be celebrated today).Finally, I will end this short blog entry on Duke’s newly-digitized collection of Istanbul postcards with this fantastic image of an old pier in the Kandilli neighbourhood of Üsküdar. The steamship and other boats (depicted on the left and center of the postcard) illustrate the importance that piers and the Bosphorus have played in Istanbul’s centuries-long history, while also giving us a glimpse (on the right-hand side of the image) of the traditional yalılar (waterfront residences and mansions), which dot the Bosphorus coast. This is a reassuring image, which suggests that whatever political and name changes the city may yet to undergo, the Abode of Happiness will remain, first and foremost, a strategically located sea port in the very heart of Eurasia.Like the previously digitized Selanik/Salonica/Thessaloniki postcard collection, the Istanbul postcards collection adds depth to Duke University Library’s holdings on the Middle East and offers yet another electronic resource for scholars of many disciplines to use for research and teaching.
Please feel free to explore the digitized Istanbul Photographs and Postcards Collection, 1890s-1930s, and see what you can discover for yourself. The images are free to download and use for research, but please cite Duke University Libraries.
Should you have questions, please contact Sean Swanick, Librarian for Middle East and Islamic Studies at Duke University.
Maybe you’re finding yourself with more free time now that all of of your social events and entertainment/shows have been canceled. Maybe you just need a break from it all. Either way now might be a great time to pick up a good book, and we still have you covered with Overdrive.
Overdrive at Duke
We have ebooks and audiobooks on a variety of subjects and genres, including graphic novels, humor, and fantasy. You just need your netID. You can borrow titles for 21 days, and you can download to all major computers and devices, including iPhones®, iPads®, Nooks®, Android™ phones and tablets, and Kindles®.
Overdrive at Your Public Library
It’s quite possible that the public library in your area has Overdrive, so take a look there too. Our friends at the Durham County Public Library has a wonderful collection that is worth checking out!
Libby
Duke Libraries is now available on the Libby app, which allows you to consolidate your checkouts across multiple libraries onto a single digital shelf. The app works with both smartphones and tablets. If you like to switch between reading on your phone and tablet, the app will sync your bookmarks and notes between devices so you won’t be left wondering where you last stopped reading. Libby also works with audiobooks!
International and area studies librarians facilitate research not only about different parts of the globe, but also about different eras in time. A prime example of this historical orientation is the recently-acquired and-digitized Selanik/Salonica/Thessaloniki postcard collection. This new addition to Duke University Library’s already extensive International Postcard Collection consists of 208 images documenting the famous Aegean Sea port-city from the late 19th to the early 20th-centuries.
Thanks to its favourable location and its large and natural seaport, this ancient city hosted merchants from near and far. In part because of its function as an international trading post, the city’s population was a mix of cultures (Armenian, Jewish, Greek, Arab, and Turk) and religions (Christianity, Judaism, and Islam). During the 20th-century, however, the formation of nation-states with regulated borders, the eruption of major wars in the region, and the consequent displacement of populations through both natural and forced migration, effectively destroyed the diversity of this multi-ethnic metropolis. The Selanik/Salonica/Thessaloniki postcard collection allows us to get a fleeting—and, therefore, all the more special—glimpse of the world that was lost as a result of war and genocide.
“What’s in a name?”
The Aegean port-city was founded in 315 BC and named after Thessaloniki (Greek: Θεσσαλονίκη), the wife of King Cassander of Macedonia and half-sister of Alexander the Great. When the Byzantine Empire – the Christianized successor to Alexander’s empire – fell to the Ottoman Turks in 1423, Thessaloniki’s days as a Greek city were numbered. In fact, just seven years later, the Ottomans captured the Aegean port city and changed its name to Selanik (Ottoman Turkish: سلانیك). The city would officially retain this name from 1430 until 1912, when Greek nationalist forces defeated the Ottomans and changed its name back to Thessaloniki.
During the long period of Ottoman rule, the city was also informally known as Salonica (Ladino: סאלוניקו). This toponym was the Ladino, or Judeo-Spanish variant of the Ottoman Turkish name for the city. Like the city itself, Ladino was a mix of cultural influences: “based in Spanish and other Iberian languages, with a strong Hebrew Aramaic component,” but also incorporating “many elements from the languages of the Mediterranean world, including Turkish, Greek, Italian, French, and Arabic.” The widespread use of the name Salonica is a reminder of the once sizable Jewish community of the Aegean port city. The Jewish population came to call Salonica home after the Reconquista and the Edict of Expulsion from Spain in 1492. However, in World War II the Jews of Salonica suffered dramatically during the Nazi occupation, which all but erased their physical presence and their role in the city’s history, save for some architectural achievements.
Wish you were here!
As the following selection of greeting cards from the digitized Selanik/Salonica/Thessaloniki postcard collection demonstrates, the creators of the images were very cognizant of the way they wished to portray their city and, therefore, very deliberate in their choice of subject matter. Everything was meant to leave the tourist who bought and sent the postcard with a positive memory of his or her visit to the city and the addressee who received it with a desire to visit it for him or herself.
The colourful postcard below, for example, displays a tranquil street scene from the usually bustling and crowded business district of Selanik. The street in question is not just any street, but the “Grand rue de la Banque Ottoman.” The influential Ottoman Bank (seen on the right) was built in 1903 by the Turkish architects Barouh and Amar with an eye to synthesizing local and European architectural aesthetics of the time. This attempt to appeal to multiple constituencies at one and the same time may explain why the title of the card is printed in both French and Ottoman.
Near the Ottoman Bank and its busy shops was the Allatini brick factory, which now sits abandoned. The brick factory was named after the family who founded it. The Allatini family was of Iberian Jewish heritage and had settled in Salonica in the early 16th century. The family would also open the Allatini flour mill, which is still in operation to this day, though now located in Sindos, a suburb of Thessaloniki. The Allatini family also owned the Villa Allatini, which is a historic building not merely because it was the family’s country estate, but also because it came to play a role in one of the most dramatic events in the history of modern Turkey. In 1908, a nationalist group called the Young Turks led a successful revolution to dethrone the Sultan of the Ottoman Empire and restore the Constitution. The Sultan was forced to abdicate and was later put under house arrest at the Villa Allatini (depicted in the black-and-white postcard below).
Other building-related postcards in the digitized collection offer views, frequently only in passing, of architectural features that are no longer a regular part of the everyday modern life. One example are the images of the sahnisi (σαχνισί), or traditional protruding balconies, which were meant to allow sunlight into a specific space of a home (as seen on the right hand side of the next image):
And this image of a sünnet bayramı (circumcision festival), a ceremony regularly held and often documented in manuscripts known as Surname-i Hümayun.
The collection ends in 1917, the year Thessaloniki was ravaged by a tremendous fire. From the dramatic image on the following postcard, it is possible to get a sense of both the magnitude of the fire as well as the terror that must have overcome the locals. The Great Fire, as it came to be known, drastically transformed the layout of the city, adding yet another layer to the palimpsest that is the history of Selanik/Salonica/Thessaloniki.
Please feel free to explore the digitized Selanik/Salonica/Thessaloniki postcard collection, and see what you can discover for yourself. The images are free to download and use for research, but please cite Duke University Libraries.
Should you have questions, please contact Sean Swanick, Librarian for Middle East and Islamic Studies at Duke University.
NOTE: Due to changes in the university’s operations in light of COVID-19, the Nadelle Prize for Book Collecting has been postponed.
Attention, student bibliophiles!
The Duke University Libraries are proud to present the 2020 Andrew T. Nadell Prize for Book Collecting. The contest is open to all students enrolled in an undergraduate or graduate/professional degree program at Duke, and the winners will receive cash prizes!
Winners of the contest will receive any in-print Grolier Club book of their choice, as well as a three-year membership in the Bibliographical Society of America.
Winners will also be eligible to enter the National Collegiate Book Collecting Contest, where they will compete for a $2,500 prize and an invitation to the awards ceremony in Washington, D.C., at the Library of Congress.
You don’t have to be a “book collector” to enter the contest. Past collections have varied in interest areas and included a number of different types of materials. Collections are judged on adherence to a clearly defined unifying theme, not rarity or monetary value.
Interested in entering? Visit our websitefor more information and read winning entries from past years. Contact Kurt Cumiskey at kurt.cumiskey@duke.edu with any questions.
by Lee Sorensen
Librarian for Visual Studies and Dance, Lilly Library
Photographs from the Collection of the Gilman Paper Company / Featured plate: Eugene Atget Rue de la Montagne-Sainte-Genevieve [PC: Metropolitan Museum of Art: Gilman Collection, Purchase, Mr. and Mrs. Henry R. Kravis Gift, 2005]What is that “big book” on display in the lobby of Lilly Library? Its proper title is Photographs from the Collection of the Gilman Paper Company. This book is a gift to Duke University Libraries from the Nasher Museum of Art, and will remain in Lilly through the spring semester.
With the rise of e-books and readers, one of the most uncommon and increasingly rare printed formats is the folio book, defined by one student as, “too damn large to carry.” In the days before book criteria included portability, giant books were produced to contain actual-size documents such as building plans and engravings, detailed scientific renderings and later, photography.
Librarian Lee Sorensen with the book Photographs from the Collection of the Gilman Paper Company
The “big book” on display is a modern edition of photographs from the Gilman Paper Company, New York. The firm had one of the best private collections of photographs in the world, which was acquired by New York’s Metropolitan Museum of Art in 2005 . This magisterial book contains reprinted photographs of photographers such as Robert Frank, Diane Arbus, Fox Talbot, Eugene Atget and Edward S. Curtis. The edition was curated by Pierre Apraxine, with plates created by renowned photographer and printer Richard Benson (who was also the Dean of Yale School of Art), and notes contributed by photography consultant Lee Marks. This volume, printed by Stamperia Valdonega in Verona, Italy, and half-bound in leather, is the only one in North Carolina outside of the Mint Museum, Charlotte.
Pages are turned periodically to show new images. 47 cm in length, the volume consists of 480 pages with 199 offset lithographs plus an offset lithographic frontispiece.
This post is by Heidi Madden, Librarian for Western European and Medieval/Renaissance Studies, and Sarah How, European Studies Librarian at Cornell University.
The Frankfurt International Book Fair is a trade event that attracts professionals from many countries and nearly all segments of the publishing and information science worlds. This includes academic librarians from the US. Every year members of the European Studies Section of the American Library Association (ALA) team up to get as much out of the Frankfurt Book Fair events as possible; they spend evenings pouring over the programs, and record what they want to report back to colleagues at the next ALA conference, including recommended readings published during the fair. For 2019, the responsibility for this task was assumed by Heidi Madden (Duke) and Sarah How (Cornell), both of whom attended the 2019 Frankfurt Book Fair and who have collaborated on the writing of this blog post.
Trade publications issued around the fair provide excellent reading for librarians. Expert White Papers (free, but registration is required for download) help visitors familiarize themselves with issues and trends before the Fair. What follows below are a few examples of our required reading for 2019.
The “Frankfurt Magazine German Stories 2019” focuses on contemporary literary markets from a trade perspective; this issue also includes a literature review on Artificial Intelligence as a topic in both in fiction and non-fiction titles.
The “Buchreport” magazine for October 2019 (free during the fair, now available for purchase), provides a statistical analysis of all major international publishing regions and identifies salient region-specific issues and trends.
Publishing Perspectives is a good journal for reading about the publishing industry year round; their daily updates distributed at the Fair are not to be missed.
As is apparent from this list, digital publishing was one of the overarching themes of the 2019 Frankfurt Book Fair. Those fairgoers who attended the sessions on publishing in the digital age were invited to enter the “VUCA World.” The VUCA world is not some happy, imaginary planet, but rather the confusing information landscape in which we all currently find ourselves: the letters of the acronym stand for Volatility, Uncertainty, Complexity, and Ambiguity. Visitors to the 2019 Fair had many opportunities to hear international experts speak on issues connected to this theme, which ran like a red (read) thread through many of the presentations. For this blog post, we have decided to focus on two of the more substantial “hot topics”: the availability of new subscription models for journals and e-books and the concept of e-books as an accessible digital ecosystem.
Library administrators and researchers from across Europe presented on Plan S, an initiative launched by Science Europe in September 2018 for making open-access science publishing a foundational principle of the scientific enterprise. There was also discussion of Project DEAL, an initiative by a consortium of German university libraries and research institutes to re-negotiate large contracts (“deals”) with the major publishing houses of e-journals, which are usually the biggest line item in any research library’s acquisitions budget. In another forum, e-book vendors approvingly noted that newspaper publishers have created innovative business models that work on the Internet by devising formulas for offering just enough free content to trigger a sale of premium content. These vendors suggested that e-books, both fiction and nonfiction, could potentially be marketed using the same sort of model, that is, by offering a preview on the Internet extensive enough to trigger either a sale of an entire volume or a “subscription” to individual chapters, one chapter at a time.
Just when publishers appear to have figured out how to monetize premium content based on the free content that appears in an Internet search, legislation triggered by the new European Union Directive on Copyright in the Digital Single Market appears to complicate matters once again. Certain aspects of the EU directive are popularly referred to as the “link-tax,” because they effectively mean that the makers of search engines can be fined for showing too much free content in the result list under a link to a content provider, especially for news content. The link tax issue is playing out in real time in France, where legislation based on the European Directive has already been introduced, and where a fierce debate between Internet giants (like Google, Apple, Facebook, and Amazon) and legislators will influence how the EU Directive is incorporated into the cyber-laws of other EU countries.
One of the most discussed topics at this year’s fair was the implementation of the European Accessibility Act, which was written on the basis of a directive by the World Intellectual Property Organization (WIPO). WIPO has 192 member states, and administers 26 international treaties, including the “Marrakesh Treaty to Facilitate Access to Published Works for Persons Who Are Blind, Visually Impaired or Otherwise Print Disabled,” which was adopted in 2013. The European Union signed the European Accessibility Act in March 13, 2019. This act directs EU member countries to incorporate WIPO’s accessibility requirements into their national laws, and to be compliant by 2025. The European Accessibility Act applies to a suite of digital services, like computer hardware and operating systems, payment terminals, websites, and e-readers. In the context of accessibility, e-books are considered a service, and the act requires that the entire publishing chain, i.e. content producers, digital distributors, catalogs for searching, and e-readers participate in making content available to Print Impaired People (PiPs). In effect, the Accessibility Act creates a vision of e-books as part of a larger and more accessible digital ecosystem.
Exemptions are planned for art books, comic books, children’s books, and smaller companies with under 2 million Euros in revenue. The print segment of the market will continue to exist, but it must align with a digital edition. For this reason, there is a provision for third party “authorized entities” to produce accessible-format copies of non-compliant publications on a non-profit basis. The work of these entities will be instrumental for foreign publishers who market materials in Europe. Organizations like Fondazione LIA, the Daisy Consortium, the World Wide Web Consortium (W3C), EDRLab, and EDItEur are working to understand the implications of this act for the publishing industry and for libraries in Europe, and are helping to develop standards for born accessible publications and for converting non-compliant publications and back files.
Fondatione LIA presented their research at the 7th International Convention of International University Presses at the Frankfurt Book Fair 2019. The full report, co-authored by Gregorio Pellegrino, Cristina Mussinelli, and Elisa Molinari: “E-BOOKS FOR ALL.Towards an accessible digital publishing ecosystem,” can be downloaded (with free registration) at the LIA website.
In sum, although we continue to live in VUCA world, the Accessibility Act, along with advances in digital publishing, search and discovery (e.g. Artificial Intelligence, algorithms, complex metadata, voice search) promise to make electronic and audio books more accessible and more functional for every reader. And American research libraries are actively helping their patrons to navigate through this changing publishing landscape. The creation of digital publishing services departments, such as the recently-founded Scholarworks at Duke or Scholarly Communications and Open Access at Cornell, is one way of engaging with the general trends and developments in the new digital publishing ecosystem. Another is to anticipate these changes by incorporating some of the proposed solutions into libraries’ strategic plans, as has been done, for example, in “Engage, Discover, Transform: Duke University Libraries,” 2016-2021. Last, but not least, is support for librarians’ attendance at international library fairs (like the one in Frankfurt), which allow librarians to stay informed about the latest developments, learn about the looming challenges, and discover innovative ways to overcome them, and inspire practical applications in their institutions.
Many organizations publish informative white papers around the time of the book fair. Pictured is the cover of ”The Universe of Books,” published by the Börsenverein des Deutschen Buchhandels in the “The Frankfurt Magazine. German Stories, 2019,” which captures the global book market.
About the authors:
Heidi Madden is the Librarian for Western European and Medieval Renaissance Studies at Duke University; she serves as Chair of the European Studies Section of the Association for College and Research Libraries.
This post is by Heidi Madden, Librarian for Western European and Medieval/Renaissance Studies, and Sarah How, European Studies Librarian at Cornell University.
International book fairs provide great opportunities for librarians to discover new books and other media; learn of new trends in publishing, translation, design, and book production; and build personal connections that directly benefit both their own work and that of their home institutions. Being abroad, being there in person, immersed in the language and culture of another place, is in itself of significant benefit, although one that is difficult to quantify. That is why we are grateful for the opportunity afforded by this library blog to write about our experiences at the 2019 Frankfurt Book Fair, and thereby to describe some of those benefits.
For international and area studies librarians, book fair visits are an essential component not only of professional development but also of collection development. That serious research libraries need materials that would not — could not, economically — be provided by our standard commercial supply channels is accepted wisdom in the profession. Book fair visits are an efficient way to address this need, since they make it possible to interact with many publishers at once, in a single exhibition space. In addition, cultural and linguistic immersion at international fairs strengthens the skills and knowledge that support research services and give academic librarians “street cred” with international students and faculty, as well as researchers engaged in foreign-language humanities, social sciences, and area studies. Visits to specialized bookstores, meetings with local librarians, and visits to local libraries and cultural institutions can be squeezed-in around a busy fair schedule for additional benefit. This is especially true for those librarians who are able to attend an international book fair in a place as rich in resources as Frankfurt, Germany.
The Frankfurt Book Fair (Frankfurter Buchmesse), an annual international event for the publishing trade community, is the world’s largest book fair. This Fair is fundamentally a commercial event, focused as it is on the business of publishing and related industries. It is the place, for example, where publishers, agents, authors, illustrators, film makers, translators, printers, authors, media specialists, book distributors, and libraries negotiate and license rights for distribution, publishing, translation, and film and media versions of the items on display. However, the Frankfurt Book Fair is also the occasion for substantial programming related to contemporary literature and, as we shall see, can even serve as a forum for robust cultural and political debates. Similarly-designed book fairs, more regional in scope, are held in Paris (Salon du livre), Bologna (Bologna Children’s Book Fair), Madrid (Liber), Guadalajara (International Book Fair), Beijing (International Book Fair), Hong Kong (Book Fair), and Moscow (International Book Fair), to name just a few.
According to established tradition, the Frankfurt Book Fair lasts for 5 days, from Wednesday to Sunday. The first three days are usually focused on exhibiting books. On those days, a European Studies librarian can, for example, peruse the publishing program of dozens and dozens of publishers from every European country, including small, independent presses. On the weekend, the fair is open to the public, and books are sold directly to individuals. On those days the sections of the fair devoted to publishers of graphic novels, cookbooks, travel literature, zines, and German language fiction are jammed with people and cosplay participants. In October 2019, 302,267 individuals from 100 countries visited the Frankfurt Book Fair. There, they were met by 7,500 exhibitors and encountered 400,000 individual books, maps, manuscripts, visual materials, and digital media objects (audio and e-books).
The special exhibit of the guest country Norway combined nature imagery, mirrors, and book tables designed to represent poems in spatial dimensions. Norway also celebrated 500 years of the printed book (Nidaros Missal and the Nidaros Breviary, from 1519) in the exhibit.
Each year, Frankfurt hosts a “Guest of Honor” country: Norway was the 2019 Guest. The guiding theme for the Norwegian events and exhibits was “The Dream We Carry.” The theme title was inspired by the famous Norwegian poet Olav H. Hauge, and his poem “It is that Dream.” Norway sponsored prominent Norwegian writers, who spoke and schmoozed with the attendees, while fair organizers produced a free bibliography of new publications from Norway in German translation to promote writers and publishers to the German reading public. Karl Ove Knausgård, a Norwegian author who has been described as one of the 21st century’s greatest literary sensations, spoke in several different settings, both about his own work and about his recent experience curating an exhibit on Norwegian painter Edvard Munch, whose best known work, The Scream, has become one of the most iconic images of world art. In other interviews, contemporary Norwegian authors Erik Fosnes Hansen and Erika Fatland covered a diversity of topics, from the Oslo cultural scene to food science, which is at the heart of Hansen’s novel Et Hummerliv (“A Lobster’s Life”). Maja Lunde spoke about her forthcoming book The End of the Ocean, while Jo Nesbø was interviewed about Knife, the next installment in his Harry Hole series of crime novels. More highlights and full listing of authors can be found in the online program.
Karl Ove Knausgård amd Jurgen Boos (CEO of the Frankfurt Book Fair)
Norwegian literature was represented by many authors reading from their work.
In addition to lectures and authors’ talks, the Frankfurt Book Fair also hosts special celebrations for the winners of the Nobel Prize, the German Book Prize, and the Peace Prize of the German Book Trade. Overall, ninety-three prizes were awarded by various organizations during the book fair in 2019. Polish-born 2018 Nobel Laureate Olga Tokarczuk (awarded in 2019) spoke at the opening session of the Fair. Oddly, Austrian-born Peter Handke, the 2019 Nobel Laureate, was not present in person, and was only represented by his publisher’s special display. Handke’s absence did not prevent him from becoming the subject of intense controversy. Saša Stanišić, the winner of the 2019 German Book Prize, who fled to Germany with his Bosnian mother and Serbian father in 1992, was the most prominent voice at the book fair, taking Handke to task for his sympathetic attitude toward former Serbian president Slobodan Milošević, the first sitting head of state to be charged with war crimes.
World newspapers, including The Guardian, chronicled the Handke debate. One of its articles, entitled “A troubling choice: authors criticise Peter Handke’s controversial Nobel win. reported on the views of famous international writers, such as Salman Rushdie, Hari Kunzru and Slavoj Žižek who opined that the 2019 Nobel laureate “‘combines great insight with shocking ethical blindness’.” Another article, entitled “Peter Handke’s Nobel prize dishonours the victims of genocide,” referenced the Austrian writer’s stance on the Yugoslav Wars in the 1990s, which has been characterized by some critics as genocide apologism. At some point during October 2019, Peter Handke announced that he would no longer speak to journalists, so for now the debate will continue in literary circles, and will most likely re-emerge around the December 10, 2019 Nobel Prize Award Ceremony.
The 2019 Peace Prize of the German Book Trade was awarded to Sebastião Salgado, the first ever photographer to receive this prize. During the course of several interviews, the Brazilian social documentary photographer and photojournalist introduced his book Gold, which showcases haunting images of Amazonia taken in the 1980s. As with his other work, Gold highlights environmental and human rights issues by investigating habitats and communities with his camera.
Cultural events inspired by Norway as the Guest of Honor were only a fraction of the international author events and talks at the Fair and in the city of Frankfurt. The gala of literary stars included Margaret Atwood, Maja Lunde, Elif Shafak, Colson Whitehead, Ken Follett, and Jo Nesbø (video Highlights can be seen on the Fair’s website). More media outlets broadcast from the book fair than can be mentioned here. The two outlets with the most video content are ARD Mediathek and ZDF Mediathek, especially the venue “Das Blaue Sofa,” which gives access to 90 interviews with authors from the Frankfurt 2019 fair alone. Social media followed along under #fmb19, and have already transitioned to the hashtag for the 2020 fair, #fbm20, as planning for the next fair gets underway. Canada will be the Guest of Honor at the 2020 Frankfurt Book Fair.
On Saturday and Sunday, while the public floods into the fairgrounds, specialized, ticketed, professional events are held at the Frankfurt Book Fair. The two that we attended this year were the 7th International Convention of University Presses 2019, which focused on the European Accessibility Act, and an event for non-fiction editors. The non-fiction publishing event “Non-fiction Publishing: It’s a Women’s World,” consisted of a panel and discussion with female publishers from Morocco, Turkey, India, and Norway, who spoke about their experiences with producing important works documenting and giving voice to issues and experiences which might not find a home with large commercial publishers.
Look for more on Frankfurt hot topics in the next blog post on Welcome to the VUCA World! The Frankfurt International Book Fair 2019. Part 2
Frankfurt Book Fair 2019 publisher displays
On Saturday, cosplay fans come dressed as their favorite characters.
“Stellt das Buch her / Make the book”: three containers stacked on top of each other, with exhibits on each level in the courtyard of the book fair.
The Most Wonderful Time of the Year is here! We are so excited for the holiday season but know how hard it is to brainstorm gift ideas. Luckily, the Duke University Libraries have two programs that provide the perfect opportunity for a thoughtful and unique present.
Adopt-A-Book
A few noteworthy first editions from the recently acquired Locus Science Fiction Foundation collection, all available for adoption.
That best friend who has seen every episode of Game of Thrones? Get them the perfect holiday gift by adopting the first book in the series, signed by George R. R. Martin himself! As part of our Adopt-a-Book Program, you can choose from a number of books and help fund their preservation in honor of someone else.
We have many titles across a variety of subjects, so you can find the perfect title that truly creates a gift like none other. An electronic bookplate with the name of the donor or honoree is added to the item’s catalog record, and they are also listed on the library website as a contributor. Gifts to the program help conserve a book and keep it available for current and future faculty, scholars, and students.
Some lovely first-editions currently available for adoption are Philip K. Dick’s Man in the High Castle (1962), Edith Wharton’s Old New York (1924), Gertrude Jekyll’s Children and Gardens (1933), Theodore Dreiser’s An American Tragedy (1925) and John James Audubon’s Birds of America (1827). Find many more at our Adopt-a-Book website.
Adopt-A-Digital-Collection
Duke football player Ken Abbott (c. 1933), from the Duke Sports Information Office Photographic Negatives Collection.
Maybe you have an uncle who loves Duke athletics but already has ten basketball jerseys? You can still give him the perfect holiday gift by adopting Photographic Negatives from the Duke Sports Information Office, a digital collection relating to all things Duke sports. Every year, we digitize thousands of items in our collections. These digital assets must be carefully managed to preserve them for generations of students and researchers to come. This work requires storage space, the specialized expertise of our talented staff, and you! Our Adopt-a-Digital-Collection program allows you to support the long-term preservation of these important cultural and scholarly resources, keeping them safe and accessible indefinitely. Each digital collection available for adoption is unique, allowing you to specialize your holiday gift to someone’s interests.
Every year the Duke University Libraries run a series of essay contests recognizing the original research of Duke students and encouraging the use of library resources. We are pleased to announce the winners of our 2018-2019 library writing and research awards.
Recognizing excellence of analysis, research, and writing in the use of primary sources and rare materials held by the Rubenstein Rare Book & Manuscript Library.
Undergraduate Prize:Sierra Lorenzini for “Fair Haired: Considering Blonde Women in Film and Advertising,” nominated by Dr. Kristine Stiles
Graduate Prize:Michael Freeman for “P. Duke Inv. 664R: A Fragmentary Alchemical Handbook,” nominated by Dr. Jennifer Knust
Recognizing excellence in undergraduate research using primary sources for political science or public policy.
Amanda Sear for “To Smoke or to Vape? E-cigarette Regulation in the US, the UK, and Canada,” nominated by Dr. Ed Balleisen
Yue Zhou for “Learning Languages in Cyberspace: A Case Study of World Languages Courses in State Virtual Public Schools,” nominated by Dr. Leslie Babinski
Valerie Muensterman for “Did You Forget Your Name?”
Caroline Waring for “The Roof”
Blaire Zhang for “Sapiens”
Join Us at the Awards Reception!
We will be celebrating our winners and their achievements at a special awards reception coinciding with Duke Family Weekend. All are invited to join us for refreshments and the opportunity to honor the recipients.
Effective September 20, 2019, the Duke University Libraries have transitioned to a title-by-title access model for Kanopy, a popular library of streaming video titles. This change comes as a result of the unsustainable increase in cost of providing unlimited access through an automatic licensing model.
Kanopy’s pricing for libraries under our previous model was based on views per title. Once a title was viewed three times for longer than 30 seconds, we were charged a licensing fee of $135 for one year of access.
Under the new model, users will still be able to watch and stream all of our currently licensed films in Kanopy (of which there are more than 800). New titles may still be requested by members of the Duke community, but they will not be accessible automatically.
We understand and respect how popular streaming media has become. It is an invaluable instructional resource and a gateway for lifelong learning. We regret having to make this change. But we could neither justify nor sustain Kanopy’s skyrocketing price tag.
Duke is not alone in having made this difficult choice. The libraries at Stanford and Harvard have also had to limit their use of Kanopy, and the New York Public Library system recently canceled their subscription to the service due to the unsustainable cost.
Here’s a summary of what’s changing:
We will only subscribe to Media Education Foundation titles on Kanopy.
Already-licensed films can still be found on Kanopy and are listed individually in our online library catalog.
All other titles may be requested via the Kanopy platform or through a course reserve request.
We will continue to accept faculty requests for Kanopy films and videos assigned in courses. If you are a faculty member, use our “Place Items on Reserve” form for these titles. If you are using a film for a class and are concerned about the expiration date of our license for it, use the same form to ensure access.
Other options for streaming and viewing video
We have a number of other streaming video platforms available to members of the Duke community. For a complete list, please refer to our Streaming Video guide.
We also encourage you to explore our extensive DVD and Blu-ray holdings, which you can find in our online catalogand have delivered to the Duke library of your choice.
For more info
For additional questions about Kanopy or about our film streaming options, please contact:
Each year the UNC/Duke Consortium for Latin American & Caribbean Studies offers competitive fellowships for scholars who want to use our library resources. Priority goes to researchers from officially recognized Historically Black Colleges and Universities, Predominately Black Institutions, Minority Serving Institutions, and community colleges. Holly Ackerman talked with the two fellows selected by the Duke Libraries for 2019-2020. The conversations will be published in two parts starting with the exchange below with Professor Shearon Roberts.
Photo: Shearon Roberts, Ph.D. Summer 2019
Tell us a little bit about yourself. Walk us through your CV.
I teach both Mass Communication and African American/Diaspora Studies courses at Xavier University of Louisiana, a historically black university in New Orleans. I earned my doctorate from Tulane University’s Roger Thayer Stone Center in Latin American Studies where I studied Caribbean media, specifically Haitian media. Prior to academia, I worked as a reporter covering Latin America and the Caribbean. I research Caribbean and Latin American media, media discourse from the region, and media discourse on race and gender.
What was your research project this summer?
It is titled, “Learning the Black Diaspora through Latin American & Caribbean Media.” After leading four years of grant-supported student field visits to Latin America and the Caribbean, the number one feedback from participating students is how much people of the region consume media about African American culture and experiences, and how little access African American students have to media about communities of color in the Americas. I want to change that through my courses and through use of materials such as those at Duke.
For example, Duke University’s Robert Hill collection provided me with a wealth of teaching resources for African American students to discover how vast and how interconnected Black Diaspora movements were. Hill’s collection dates back to Marcus Garvey and the UNIA (founded in 1914), and he is also the executor for C.L.R. James’ (1901-1989) work. It was fascinating to see how closely Black movements in the Caribbean were intricately connected to African American movements and African movements. Hill also dedicated himself to the teaching of the Black Diaspora and within his collection are both his and his contemporaries’ syllabi – a valuable find for re-introducing materials out of print or that have been ignored in the teaching of the Black Diaspora in the Americas. Below are two sample teaching guides/syllabi I found in the Robert Hill collection at the Rubenstein that I will use for teaching my courses:
Source Citation: Hill Personal Box 14, Robert A. Hill Collection, David M. Rubenstein Rare Book & Manuscript Library, Duke University.
For my own research, Hill’s collection was invaluable in laying out Caribbean intellectual thought and movements and how Caribbean intellects connected to media and to the public. I originally applied for the College Educators Research Fellowship (CERF) to research the Radio Haiti Archive’s non-digitized records and I was not disappointed. The archive is not just a Haitian one, but a Caribbean one, and it provided a window on many of the movements taking place around the region. The Radio Haiti archives are impeccably well-cataloged, a nod to the archivist Laura Wagner’s hard work. Because of the archives’ detailed descriptions, I located a little-known dissertation from the eighties, well at least little-known to me, documenting press history in Haiti. I also discovered through this archive how regional in scope many important media outlets in the Caribbean were during this time.
Source Citation: Radio Haiti Box 14: Aux Origines De La Presse Folder, Radio Haiti Papers, David M. Rubenstein Rare Book & Manuscript Library, Duke University.
Both staff at the Rubenstein and the UNC-Duke Consortium in Latin American and Caribbean studies were extremely helpful in shaping a successful visit to Durham this summer. Patrick Stawski pointed me in the direction of the Ecumenical Program on Central America and the Caribbean (EPICA) records and helped me to conceptualize a project from this collection that I had not conceived of prior to my time at the Rubenstein. Sara Seten Berghausen helped me navigate digital collections and took time to send me documents from digital collections for course teaching. Corin Zaragoza Esterra helped me think through the connections of my research projects and find my away around Durham during my stay. Natalie Hartman made sure that my access to Duke’s resources were seamless. I thank all the staff at the Rubenstein who worked with lightning speed to ensure I had access to every rare material requested during my stay. Finally, I am extremely grateful to Holly Ackerman for getting me to think across the collections and starting me off in the right scholarly directions before and during my stay.
How will the info you gathered at the Duke Libraries be used?
I have updated my coursework and course lectures to include materials I researched at the Rubenstein. I have incorporated materials from digital collections for course unit assignments. These range from sections of constitutions from the region to photographs showing civic activism in the region, and music and films from the region. My research, both current and those in development stages have been greatly enhanced by documents located in these collections. The manuscripts I am writing about Haitian media, Caribbean media and Caribbean movements will include documents from the collections of the Rubenstein.
This month’s Collection Spotlight is featuring microhistories. In order to create what we hope is a far ranging and interesting selection of titles for people to browse, we decided to approach microhistory both from the academic and popular side of things. We hope you will forgive us if in our enthusiasm we stray into some titles that might not meet the strict definition!
Here is a selection of some of the titles that we are showcasing:
If some of these titles spark your interest, consider getting involved with Duke’s own MicroWorlds Lab this year! They even have a section called “What is Microhistory” if you want to explore further what this method of study means.
Please check out the Collection Spotlight rack near our Perkins Library Service Desk on the first floor of Perkins to find your next read!
Toni Morrison passed away yesterday at the age of 88. You can find a lot of really wonderful tributes and reflections online explaining just why she is a literary giant. Here are a few that you might find interesting:
If you have a chance to go see the new documentary on her, Toni Morrison: The Pieces I Am, you should definitely do so. I saw it at the Full Frame Documentary Festival this year, and I really enjoyed it. Eventually we’ll have a copy of the dvd in our library, but in the meantime you might enjoy these two films:
This month’s Collection Spotlight in Perkins Library explores foodways of the southeastern United States. People come to Duke from all over the world, and while they’re here, they will undoubtedly eat. We invite you to reflect on the cultural importance of food in this region, whether you’re here for life or just a little while.
We’re featuring books that explore the intersections of food with race and class and gender. We’ve tried to represent some of the regional diversity in southern food, from Appalachia to the Piedmont, the Low Country to the Gulf Coast, and some of the diversecultures that contribute to southern food today. We’re thinking about politics and history and personal stories. And we hope there’s something for everyone, whether you’re interested in food studies theory and methods, a recipe for your evening meal, or even poetry.
Of course, some of the hottest titles are perpetually checked out, and for those you’re invited to submit an interlibrary request (tip: you can just use the green “Request” button when you search for a book and it will populate the form). Of course, we also have many eBooks you won’t see on display, so don’t forget to check the catalog.
Come take a peek next to the Perkins Library Service Desk, though we can’t promise you won’t leave hungry.
The Locus collection includes some 16,000 rare and noteworthy monuments of science fiction and fantasy, many in their original dust jackets.
The David M. Rubenstein Rare Book & Manuscript Library at Duke University has acquired the archives of the Locus Science Fiction Foundation, publisher of Locus, the preeminent trade magazine for the science fiction and fantasy publishing field.
The massive collection—which arrived in almost a thousand boxes—includes first editions of numerous landmarks of science fiction and fantasy, along with correspondence from some of the genre’s best-known practitioners, including Isaac Asimov, Arthur C. Clarke, Ursula K. Le Guin, Harlan Ellison, Octavia E. Butler, James Tiptree, Jr. (Alice Sheldon), Dean Koontz, Robert A. Heinlein, and hundreds more.
Locus started out in 1968 as a one-sheet science fiction and fantasy fanzine. Since then, it has evolved into the most trusted news magazine in science fiction and fantasy publishing, with in-depth reviews, author interviews, forthcoming book announcements, convention coverage, and comprehensive listings of all science fiction books published in English. It also administers the prestigious annual Locus Awards, first presented in 1971, which recognize excellence in science fiction and fantasy.
Over the course of five decades in print, the magazine’s editors and staff have collected and saved correspondence, clippings, and books by and about science fiction, fantasy, and horror writers. What emerges from this trove of material is a tapestry of a diverse and thriving community of writers, publishers, and editors, all working to create new and modern genres of speculative literature.
This rare advanced reader’s copy of the first edition of Game of Thrones has a distinctly different look and feel from the popular HBO series.
Of the magazine’s original three co-founders—Charles N. Brown, Ed Meskys, and Dave Vanderwerf—only Brown remained after the magazine’s first year. He would continue to edit the publication until his death in 2009, earning the magazine some thirty Hugo Awards in the process and becoming a colorful and influential figure in the publishing world. A tireless advocate for speculative fiction, Brown was also a voluminous correspondent and friend to many of the writers featured in the magazine. Many of them wrote to him over the years to share personal and professional news, or to quibble about inaccuracies and suggest corrections. The letters are often friendly, personal, humorous, and occasionally sassy.
Reacting to a recent issue of Locus that featured one of her short stories, the science fiction writer Octavia E. Butler wrote, “I am Octavia E. Butler in all my stories, novels, and letters. How is it that I’ve lost my E in three places in Locus #292? Three places! You owe me three E’s. That’s a scream, isn’t it?”
One also finds frequent remembrances and retrospectives of departed members of the Locus community, such as Ursula K. Le Guin’s poignant reflections on the passing of Philip K. Dick. After Brown’s own death, the magazine continued publication under the auspices of the Locus Science Fiction Foundation, a registered nonprofit. The magazine launched a digital edition in January 2011 and has published both in print and online ever since.
In addition to the correspondence, story drafts, and other manuscript material (which has now been processed), the collection includes some 16,000 rare and noteworthy monuments of science fiction and fantasy from Brown’s extensive personal library, such as first editions of Isaac Asimov’s I, Robot, Ray Bradbury’s The Martian Chronicles, Robert E. Howard’s Conan the Barbarian, J. R. R. Tolkein’s Lord of the Rings trilogy, Frank Herbert’s Dune, and hundreds more.
“Historical literary treasures abound in the Locus collection, from full runs of the pulps to vintage first editions to contemporary works,” said Liza Groen Trombi, Publisher and Editor-in-Chief of Locus Magazine. “And its preservation is deeply important. It is the product of decades of collecting and curating, starting in the 1940s, the Golden Age of science fiction, when Locus’s founding publisher Charles N. Brown was an avid reader with a deep love of genre, through his time working within the science fiction field, and up to the present day under the current Locus staff. Housing those core works in an institution where they’ll be both accessible to scholars and researchers at the same time as they are carefully preserved is a goal that I and the Locus Science Fiction Foundation board of directors had long had. I am very happy to see them in the dedicated care of the curators and librarians at Duke.”
“The opportunity to acquire the Locus Foundation library is a tremendous one for Duke,” said Sara Seten Berghausen, Associate Curator of Collections in the Rubenstein Library. “Because it’s a carefully curated collection of the most important and influential works of science fiction of the last several decades—most in their original dust jackets, with fantastic artwork—it complements perfectly our existing collection of utopian literature from the early modern period through the mid-twentieth century.”
Locus started out as a one-sheet science fiction and fantasy fanzine and grew into the most trusted news magazine in science fiction and fantasy publishing.
Berghausen notes that Brown and Locus created not only this collection, but a community of writers, and those relationships are documented throughout the archival collection as well. “The research and teaching possibilities are almost unlimited,” she said. “From political theory to history, art, anthropology and gender studies, there are materials in the collection that could enrich the study of so many topics.”
The collection is already being used in courses at Duke. This semester, English professor Michael D’Alessandro brought his class on utopias and dystopias in American literature to the Rubenstein Library to examine some of the Locus materials first-hand.
“It’s a curious strength Duke has that I didn’t expect,” said D’Alessandro. “I taught this course previously at Harvard, and even the archives there didn’t have anything like this collection, which adds a whole new breadth and depth to the class.”
WHEN: Thursday, April 25, 4:00 – 6:00 p.m. (Reception at 4:00, with program starting at 4:30 p.m.)
WHERE: Korman Assembly Room (Perkins Library Room 217), Perkins Library 2nd Floor, Duke West Campus (Click for map)
Walt Whitman, who was born 200 years ago this spring, once wrote:
Shut not your doors to me, proud libraries, For that which was lacking among you all, yet needed most, I bring.
He was probably not talking about chocolate. But that won’t stop this proud library from bringing some to his birthday party!
Join us on April 25 as we celebrate Whitman’s bicentennial, with readings and remarks by Richard H. Brodhead, Duke’s ninth president, on why he loves the “Good Gray Poet” and you should, too. If you’ve ever wanted to know more about America’s most famous bard, now is your chance to take a short course (with no grades or quizzes!) from one of the foremost experts on the subject.
Guests will also be invited to view original Whitman manuscripts and materials from the David M. Rubenstein Rare Book & Manuscript Library, which holds one of the largest and most important Whitman collections in the world, right here at Duke.
Free and open to the public. And yes, there will be chocolate.
About Richard H. Brodhead
Richard H. Brodhead served as President of Duke University from 2004 to 2017. As President, he advanced an integrative, engaged model of undergraduate education and strengthened Duke’s commitment to access and opportunity, raising nearly $1 billion for financial aid endowment. Under his leadership, Duke established many of its best-known international programs, including the Duke Global Health Institute, DukeEngage, and Duke Kunshan University. Closer to home, Duke completed major renovations to its historic campus and played a crucial role in the revitalization of downtown Durham.
Brodhead received his B.A. and Ph.D. from Yale University, where he had a 32-year career as a faculty member before coming to Duke, including eleven years as Dean of Yale College. A scholar of American literature and culture, he has written and edited more than a dozen books, including on Hawthorne, Melville, and Whitman. He was elected to the American Academy of Arts and Sciences in 2004, and he was named the Co-Chair of its Commission on the Humanities and Social Sciences and co-authored its 2013 report, “The Heart of the Matter.” He has been a trustee of the Andrew W. Mellon Foundation since 2013.
Brodhead’s writings about higher education have been collected in two books, The Good of this Place (2004) and Speaking of Duke (2017). For his national role in higher education, Brodhead was given the Academic Leadership Award by the Carnegie Corporation of New York. He is currently the William Preston Few Professor of English at Duke.
The 61st Annual Grammy Awards wrapped up in February, and now is your chance to catch up with some of the critically-acclaimed recordings that you may have heard about but haven’t had a chance to audition yourself. The Duke Music Library is pleased to unveil a new collection spotlight of recordings nominated for the 2019 Grammy awards, featuring more than 80 albums from just about every category you’ve heard of – and some you might not have!
In addition to some of the finest recordings from the last year in Opera, Musical Theatre, and Classical, this collection spotlight includes Cardi B, Ariana Grande, Kacey Musgraves, Beck, Fred Hersch, Drake, Joshua Redman, Kurt Elling, Buddy Guy, High on Fire, and many more.
French countertenor Philippe Jaroussky is among the most famous countertenors in the world right now, and it’s a voice range that has attracted growing interest in recent years. The high range of the countertenor voice and the manner in which its unusual qualities are produced results in a sound that has often been described as unearthly – it’s also a powerful and flexible voice type, able to handle music of stunning virtuosity and highly expressive pathos. All of these qualities are beautifully demonstrated in this album of arias selected by Jaroussky from among lesser-known Handel operas, highlighting pieces which he says “reveal a more intimate, tender side of Handel.”
Preview an incredible aria from the album, “Sussurrate, onde vezzose” from Handel’s Amadigi di Gaula, which evokes the limpid and gentle murmuring of waves. Jaroussky begins with an almost impossibly hushed suspended note on the word “whispering.”
Fred Hersch and company continue to find new and innovative modes of expression within the jazz piano trio context. Featuring new Hersch originals alongside fresh interpretations of a few standard tunes, this album really shines, both in recording quality and inspired live performance.
-Jamie Keesecker, Stacks Manager and Student Supervisor, Music Library
Metal lifer Matt Pike gets the big nod after a year in which this release was not even the best thing he put out (that distinction would go to his other band Sleep’s album ‘The Sciences’). It was also a year in which he had a public struggle with diabetes that cost him a toe and grounded a large part of the tour for ‘Electric Messiah’. That said, when the award was announced early in the Grammy ceremony, the cameras spent many long seconds scanning back and forth looking for the winners in a mostly-deserted theater. Finally, from way in the back, Pike hobbled forward with the help of a cane, and accompanied by his metal peers, to accept his shiny statue. “We never really need an award for doing what we love…” was part of Pike’s on-stage comment, but the commendation was very cool all the same.
– Stephen Conrad, Order Specialist for Music and Film and Team Lead for Western Languages, Monographic Acquisitions
The new Kernis Concerto was written for Canadian violinist James Ehnes, and it really serves as a showcase for Ehnes’ strengths. He comes across as such an intelligent musician, really playing with (not just in front of) the other members of the orchestra – Kernis gives them some great moments of interplay here. This work also balances Ehnes’ ability to deliver beautifully straightforward, unfussy lines one minute and astoundingly virtuosic cadenzas the next. Oh, and apparently he watched his Grammy win on a live stream in his neighborhood grocery store parking lot. How much more Canadian and unpretentious can you get?
-Sarah Griffin, Public Services Coordinator, Music Library (and, yes, a violinist)
Come over to East Campus to see these and browse through many more on our display of CDs. Don’t have a CD drive on your laptop anymore? No, neither do we! Borrow a portable DVD/CD drive while you’re here.
Fans of accompanying visual materials may find these albums to be of particular interest:
Wayne Shorter’s immersive Emanon, packaged with its accompanying graphic novel by comic book artist Randy DuBurke.
The Berliner Philharmoniker’s 6-disc box set (4 CDs and 2 Blu-ray discs), The John Adams Edition, featuring the music of legendary minimalist composer John Adams, with photographic artwork by Wolfgang Tillmans. Recorded during the orchestra’s 2016/2017 season during which Adams served as Composer in Residence.
At the Louisiana Hayride Tonight, a massive 20-CD box set with 224-page hardcover book documenting the storied radio program broadcast live from the Municipal Auditorium in Shreveport, Louisiana between 1948 and 1960. Includes a previously unreleased recording by Hank Williams, as well as rare gems from Johnny Cash, Kitty Wells, Elvis Presley, and many more.
Battleground Korea: Songs and Sounds of America’s Forgotten War brings together an assortment of songs, news reports, public service announcements, and other spoken-word audio (including a plea for blood donations from Howdy Doody) on four CDs, accompanied by a full-color hardcover book featuring song and artist information, record covers, advertisements, propaganda posters, and rarely-seen photographs from the war.
Please join us for an event celebrating the Lisa Unger Baskin Collection and the work of our amazing staff!
Phillis Wheatly, Poems on Various Subjects, Religious and Moral. Lisa Unger Baskin Collection.
Date: Friday, April 12 Time: 11:00-11:45 am Location: Holsti-Anderson Family Assembly Room, Rubenstein 153
In April 2015, the Lisa Unger Baskin Collection arrived at the David M. Rubenstein Rare Book & Manuscript Library at Duke University. Comprising over 11,000 rare books and thousands of manuscripts, journals, ephemera, and artifacts, the Baskin Collection includes many well-known monuments of women’s history and arts as well as lesser-known works produced by female scholars, printers, publishers, laborers, scientists, authors, artists, and political activists. “From Shipping Crate to Exhibit Case” looks at the comprehensive work of libraries, including how we organize, conserve, describe, and exhibit, through the lens of this unique collection.
“Five Hundred Years of Women’s Work: The Lisa Unger Baskin Collection” will be available for viewing after the program, in the Mary Duke Biddle Room.
Who is the best superhero or superhero faction? Does the Marvel Universe or DC Comics reign supreme? The decision is entirely in your hands if you enter Lilly Library’s March Movie Madness! While the battles for the rounds of 64 and 32 occurred on Knowhere and Xandar respectively, we announce that Super Sixteencombatants remain. Now the war has arrived on Earth (or, at least, Lilly Library) and it’s time to crown our champion!
This year’s Lilly Library March Movie Madness begins Monday, March 18th. It’s YOUR turn to enter into the fray and vote in the evolving brackets to help decide our ultimate superhero! And, yes – there are prizes!
BRACKETOLOGY by Nathaniel Brown
Lilly Library’s Expert Bracketologist Nathaniel Brown
In the Gotham bracket, will the hometown advantage aid the Caped Crusader to pull out the victory and advance to the Fantastic Four? Which version of the Dark Knight will advance – the sarcastic and brooding Lego version, or the equally brooding, looking to retire Christian Bale version? Will the God of Thunder electrify Gotham instead? Or will the King of Atlantis flood the city?
In the Metropolis bracket, will the animated family of the Incredibles overtake the Xavier led group of mutants? Will the Man of Steel preserve home field and annihilate the First Avenger?
In the majestic bracket of Paradise Island, will Wonder Woman continue her blockbuster success and dethrone the wisecracking Deadpool? Will the Spider multiverse pelt the suit of the Man in a Tin Can with his web shooters?
Lastly, in the Wakandabracket, will the all-powerful Justice League defeat the Guardians of the Galaxy (who always seem to have their own personal agendas but come together when it counts)? Or will the King of Wakanda pounce and maul the opposition provided by the Web-slinger?
*NOTE: Participants who provide their Duke netID and compete in all the brackets to vote for our CONQUERING HERO, will be entered into Prize Drawings for Student CRAZIES and for stalwart Duke Staff.
Do You Have Nerves of
Superman: Man of Steel
To Take It All The Way?
Here’s to a great adventure as we all advance through the Lilly Library March Movie Madness Superhero Brackets to crown the Conquering Hero!
Contributors: Nathaniel Brown, Lilly Library Media and Reserves Coordinator Carol Terry, Lilly Library Collection Services & Communications Coordinator
Women’s work. The phrase usually conjures up domestic duties or occupations largely associated with women—such as teaching, nursing, or housekeeping. The Lisa Unger Baskin Collection upends those associations. By bringing together materials from across the centuries, Baskin reveals what has been hidden—that Western women have long pursued a startling range of careers and vocations and that through their work they have supported themselves, their families, and the causes they believed in.
In 2015, Lisa Unger Baskin placed her collection with Duke’s Sallie Bingham Center for Women’s History and Culture, part of the Rubenstein Rare Book & Manuscript Library. Comprising more than 10,000 rare books and thousands of manuscripts, journals, items of ephemera, and artifacts, it was the most significant collection on women’s history still in private hands—an enormous body of material focusing on women’s work in all its diversity.
This exhibition provides a first glimpse of the diversity and depth of the collection, revealing the lives of women both famous and forgotten and recognizing their accomplishments.
After its premiere at Duke, the exhibit will travel to New York City and be on display at the Grolier Club, America’s oldest and largest society for bibliophiles, December 11, 2019 – February 8, 2020.
To accompany the exhibition, the Rubenstein Library and the Grolier Club have co-published a 160-page full-color catalog, which will be available for sale at the opening reception on February 27, and at a related symposium on “Women Across the Disciplines,” scheduled for April 15-16, 2019, at the Rubenstein Library.
Free guided tours of the exhibition will be offered every Friday at 2:00 p.m. and 3:00 p.m., March 8 – June 14. Sign up for a tour online.
The exhibition catalog was co-published by the Rubenstein Library and the Grolier Club.
Exhibit Opening and Reception: Please Join Us!
Date: Wednesday, February 27 Time: 5:00 – 7:00 p.m. Location: Gothic Reading Room and Ahmadieh Family Commons, Rubenstein Library 2nd Floor
Featuring collector and exhibit co-curator Lisa Unger Baskin in conversation with Naomi L. Nelson, Associate University Librarian and Director, Rubenstein Library. Also featuring introductory remarks by Edward Balleisen, Vice Provost for Interdisciplinary Studies. Free and open to the public.
Duke historian John Hope Franklin (left) and political scientist Samuel DuBois Cook, both of whom are featured in the HistoryMakers database of oral history interviews.
Guest post by Heather Martin, Librarian for African and African American Studies
Looking for oral history interviews of African Americans? Try The HistoryMakers Digital Archive, a new subscription database available through Duke University Libraries.
HistoryMakers contains over 10,000 hours of video interviews with African-Americans distinguished in the categories of education, media, science, politics, law, the arts, business, medicine, the military, sports, religion, entertainment, and other areas of public life. Interviewees discuss memories from the 1890s to the present. The project currently includes original interviews of more than 2,000 individuals, with a goal of collecting 5,000 interviews.
By creating story segments from each interview, HistoryMakers allows users to find relevant discussions on specific topics. Interview transcripts are searchable, but you can also choose from a list of story topics (e.g., leadership, desegregation/integration, public health issues, philanthropy, role models, gender identity, faith, humorous story quality, and arguing a position). You can also create shareable playlists by selecting stories from your search results.
A search for “Duke University” reveals hundreds of interviews with noteworthy individuals, including Paula McClain, current dean of Duke’s Graduate School.
A search for Duke University retrieves 321 stories, including interviews with noted historian John Hope Franklin; Samuel DuBois Cook, the first African American professor at Duke; Vera Ricketts, the first black female pharmacist at Duke University Hospital; and Paula D. McClain, current dean of the Graduate School at Duke.
Winter Break is approaching, and soon our Duke community will spread out across the country and the globe, heading home for the holidays or partaking in some much-needed travel.
Even if you’re just planning on curling up with a good book at home (admittedly, one of our favorite activities), the Libraries have collected works to add some adventure into any kind of vacation. The newest display, located next to the Perkins Service Desk, features books on all things travel-related. The display combines traditional travel narratives with fiction, including journeys and time travel.
Here’s the complete list of “Books to Take You Places,” with links to where you can find them in our catalog. Read them now, or just add them to your Goodreads list for later. Happy reading!
Halloween may be over, but that doesn’t mean you can’t still get your scare on!
Check out Lilly Library’s collection spotlight on books and movies that celebrate Frankenstein’s 200th birthday and comprise a ghoulish grouping of truly terrifying titles….
Lilly’s collections include books on philosophy and ethics, graphic novels, art and visual studies, and film. To commemorate the 200th anniversary of the publication of Mary Wollstonecraft Shelley’s enduring tale, Frankenstein; or the Modern Prometheus, both Lilly and Perkins are highlighting their titles on the subject. At Lilly we’ve thrown in additional scary movies to add to the horror. Enjoy the holiday chills!
This comes in response to numerous requests over the last few years. We have a new deal for all currentJoVE titles (see title list and details below). While the official start date is January 2019, JoVE has already opened up full access to Duke IP addresses.
What is JoVE?
JoVE publishes peer-reviewed videos of people doing real-world scientific experiments. By letting you watch the intricate details of experiments rather than just read about them in articles, JoVE helps you understand how to recreate those experiments, thereby improving research productivity, reproducibility, and student learning outcomes.
How and why to use it
JoVE funded a study of the impact on student performance of watching their videos prior to lab classes. A description of the study and a link to download the resulting whitepaper can be foundhere.
The JoVE blog also has a number of posts giving examples of how faculty are using JoVE in their teaching and research. For example:
Dr. Dessy Raytcheva at Northeastern University uses JoVE videos as pre- and post-assignments in her undergraduate biology course, in order to save class time for higher impact teaching activities.
Marilene Pavan, manager of Boston University’s DAMP lab credits publishing video protocols in JoVE with significant increases in experimental success rate and reduction in errors.
Given the high subscription costs for this product, we will be looking at usage statistics and impact stories to determine whether to continue after an initial three years. So if you use JoVE in your research or teaching, please let us know!
Our new deal includes perpetual access to video articles published under most of the JoVE journal titles, even if we don’t continue subscribing to new content. For a few titles (those that are more clinical in focus or for which we have received the fewest requests), we will only have access through December 2019, unless we decide to expand even further. For the remaining titles, we will have access as long as we continue to subscribe.
Please contact DUL science librarians at askscience@duke.edu if you have any questions or comments. We are also happy to provide links to support documentation, such as instructions for embedding JoVE videos in Sakai.
Although classes have started and September is here, it’s still doggone hot outside. In honor of these waning dog days of summer, Lilly Library has curated a selection of dog books and films for you to enjoy (with or without your furry friends!) in the comfort of the A/C. Here are some of my personal favorites from our Collection Spotlight.
One of my favorite mockumentaries, Best in Show lampoons dog shows and the people who obsess over them. If you’ve seen a Christopher Guest directed film before (Spinal Tap, Waiting for Guffman, A Mighty Wind) lots of the usual suspects show up in this one, including Michael McKean, Jane Lynch, and Eugene Levy. Highly recommended for bloodhound fans.
Even if you’re not familiar with the name William Wegman, I’m willing to bet you’ve seen one of his photographs. Wegman is most famous for his many photos of his gray Weimaraner hunting dogs, who are often posed on furniture or wearing costumes. A wonderful book of phodography!
An exhibition catalog from the Berlin Museum of Prints and Drawings, this book contains depictions of canines in art ranging from medieval times to the modern era. Recommended if you want to get a broad sampling of dogs in art.
No actual dogs involved in this one, but it does feature the oppressive heat we’re currently facing here in Durham. Set during a steamy afternoon in New York City, this Sidney Lumet film follows two bank robbers (Al Pacino and the excellent John Cazale) as their plans go sideways and they are forced to improvise. This film is a must-watch masterpiece.
Drop by Lilly Library and check out the Collection Spotlight stand to the left of the front desk for more dog-themed books and films!
… What are the libraries’ hours? … How do I find a book? … Who can help me with research? … Where can I print?*
Duke’s newest students can find the answers to these questions – and more – on the Library’s Services for First-Year Students page.
Lilly Library on East Campus
Each August, a new class of undergraduates arrives in Durham ready to immerse themselves in the Duke Community. Duke University Libraries serve as the core of intellectual life on campus. Because East Campus is home to the First-Year students, Lilly and Music Libraries have the unique opportunity to introduce our newest “Dukies” to the array of Library resources and research services available.
To help navigate the vast library resources, there is a portal especially for First-Year Students. Through this portal page, new students (and even some not-so-new) can discover all that the Duke University Libraries offer:
A new exhibit on the second floor of Bostock Library, next to the East Asian Magazine Reading Room, explores the truly global popularity of graphic novels.
Since ancient times, human beings all over the globe have been bringing text and images together to tell stories. The term “graphic novel” connotes a full-length graphic narrative that uses sophisticated artwork to address serious literary themes for mature audiences. Starting in the 1980s, it gained popularity as an alternative to comics in Britain and America. However, this distinction between “lowbrow” comics and “highbrow” graphic novels is not relevant to Europe, Latin America, and Asia, which have long histories of narrative art that appeals to a wide range of audiences in many genres.
In this selection of graphic novels and cartoons from Duke’s collection, you will see retellings of classics and tales of adventure that have gained massive popularity in Japan and China. You will see stories of revolution and bold political movements from Russia, India, South Africa, and Colombia. You will see tales of atrocities, survival, and redemption in Germany and Israel. You will see humor, both lighthearted and political, in Turkey, Portugal and Spain, and everyday life in Korea and Côte d’Ivoire. This variety demonstrates the power of graphic narratives to reflect and lend new visual interpretations to all aspects of the human experience. We welcome you to explore one of the world’s most popular modes of storytelling in the Duke collection.
The exhibit was curated by Katie Odhner, a graduate student in the UNC School of Information and Library Science who is interning this summer with our International and Area Studies department.
The American Dance Festival kicked off its 41st year in Durham this June 2018. Lilly Libraryis celebrating with an exhibit and collection spotlight highlighting our diverse range of books and films related to dance.
Duke University Libraries house the ADF Archives, including its Moving Images Collection of approximately 2,000 films and videos from 1930 to the present. These videos capture dance classes, panels, performances, discussions, showings, interviews and special events. Many can be viewed on-site in Lilly. Stop by and check us out!
ADF Extra:
Saturdays in June and July, view Movies By Movers, at the Nasher Museum of Art and White Lecture Hall on Duke’s East Campus. This ADF series is a bi-annual festival dedicated to the celebration of body and the camera. A full screening schedule can be found here.
Our Lilly Collection Spotlight shines on talented Duke Alumni including authors, broadcasters, researchers, as well as many who are accomplished in popular entertainment – both on screen and behind the scenes. Their studies while at Duke are varied, and for many, their majors were not directly related to their career. The featured books encompass a range of genres and styles – from sociological research to critically acclaimed fiction to sports journalism. Duke alumni working in film and television produce and appear in a variety of films including comedies, drama and thoughtful documentaries. Actors, directors, writers – they experience success both in front of the camera and behind. What they all have in common is their “Duke experience”.
Check out the entire list of books in the Lilly Collection Spotlightand visit Lilly Library to view the exhibit Duke Alumni on the Screen and Behind the Scenes.
Pulitzer Prize winner and American master Anne Tyler’s inspired, witty and irresistible contemporary take on one of Shakespeare’s most beloved comedies. Tyler graduated from Duke in 1961.
The Legends Club : Dean Smith, Mike Krzyzewski, Jim Valvano, and an epic college basketball rivalry
In the skillful hands of John Feinstein (Duke 1977), this extraordinary rivalry–and the men behind it–comes to life in a unique, intimate way. The Legends Club is a sports book that captures an era in American sport and culture, documenting the inside view of a decade of absolutely incredible competition.
Dollars and sense : how we misthink money and how to spend smarter
Dollars and sense : how we misthink money and how to spend smarter Bestselling author (Predictably Irrational) and behavioral economist Dan Ariely (PhD Business 1998) teams up with financial comedian and writer Jeff Kreisler to challenge many of our most basic assumptions about the precarious relationship between our brains and our money.
The Gaza Kitchen: a Palestinian culinary journey
This is a richly illustrated and researched cookbook that explores the distinctive cuisine of the area known prior to 1948 as the Gaza District–and that of the many refugees who came to Gaza in 1948 and have been forced to stay there ever since. In summer 2010, Laila El-Haddad (Duke 2000) and Maggie Schmitt traveled throughout the Gaza Strip to collect the recipes and shoot the stunning photographs presented in the book.
Forever Duke: On the Screen and Behind the Scenes
Accompanying the books in the Collection Spotlight, the current exhibit in the Lilly Library foyer is Forever Duke: On the Screen and Behind the Scenes. The works of Duke alumni filmmakers, writers and actors featured include films and series found in the Lilly Library collections. A few of the more well known titles or personalities:
We Were Soldiers – directed by Randall Wallace (’72)
We Were Soldiers Directed by Randall Wallace (’72) Wallace wrote and directed We Were Soldiers. Nominated for an Oscar as screenwriter for Braveheart, he also worked on films such as Pearl Harbor and The Man in the Iron Mask.
Community and The Hangover
Community featuring Ken Jeong
Ken Jeong (’90) was a premed student at Duke. A licensed physician, Jeong found fame in comic roles in both television and film.
Other Duke luminaries include actress and Baldwin Scholar Annabeth Gish (’93) who stars in the current X-Files, Martin Kratt (’89), the co-creator of the beloved children’s series Zoboomafoo and Wild Kratts, Oscar and BAFTA nominee cinematographer Robert Yeoman (’73) , film editor Alisa Lepselter who has worked on Woody Allen films such as Midnight in Paris and Match Point, and documentary filmmakers Ryan White (’04) and Rossana Lacayo (’79).
The Duke campus and Durham have also been featured in film and television; productions include Bull Durham, The Handmaid’s Tale (the film), The Program, Main Street, Iron Man 3, Kiss the Girls, Brainstorm and the late 1990’s coming-of-age television series Dawson’s Creek. Whether it’s American Pie 2, Mystic Pizza, The Squid and the Whale or Parks and Recreation, you will find a Blue Devil!
There is No Crying in Baseball –
Three of the Elite Eight are Baseball movies!
A League of Their Own turned off the Friday Night Lights for good, and Moneyball and 42 continued to score on the field. Alas, local favorite Bull Durham discovered that it is all “sunshine” as Remember the Titans piled on. Rocky may have knocked out When We Were Kings, but he’ll soon to have face the GOAT Michael Jordan and teammates when it is game time in Space Jam! Can the youngsters Karate Kid and Creed prevail?
NEW VOTERS are welcome! It’s not too late to vote in the Elite Eight,then on Saturday 3/31 make your picks for the Final Four and the Championship round on Monday 4/2. Vote here
Who’s left? Pick your brackets and VOTE in the Elite Eight
Extra Innings? OT? Bonus points?
We have more sports movies to recommend – check out the bench-warmer roster at March Madness-On The Bench
Remember, if you submit your Duke NetID, you may win a CRAZIE prize!
March Movie Madness @ Lilly begins Monday, March 19th.
Lilly Library has 100s of sports films – ranging from iconic classics such as Rocky to quirky films like Shaolin Soccer to searing dramas such as Creed. In fact, we have so many sports films, we decided to select just 64 (sound familiar?) for our very own Lilly Library version of March Madness. You may not agree with our title selections (does that also sound familiar?), but don’t let that stop you from joining in the fun and having a chance to win a Crazie great PRIZE!*
Here’s how:
To vote, visit our 64-team Lilly Library March Movie Madness online field. Round two is now open for votinghere!
To record your selections, vote for your choice of Heavy Hitters in Bracket A versus films that Go the Distance in Bracket B to eventually face those films that are Down to the Wire in Bracket C opposite the Full Court Press of Bracket D. Voting dates are listed below and on the contest page.
Updates will be posted in Lilly Library’s lobby and on Lilly’s Facebook, Instagram and Twitter accounts in addition to our blog, Latest@Lilly.
There was lots of action in the 1st Round of Lilly Library’s March Movie Madness brackets. Looks like “The Dude” was “Blind Side-d”, Caddyshack may have what it takes to be a Cinderella story, the Karate Kid “waxed off” Hoosiers, and TalladegaNights did a “Shake’n Bake” all over the Field of Dreams.
Winner announced: Wednesday, April 4th!
Bonus: Extra Innings? Overtime? Want MORE sports movies?
Some movies are so iconic that they are more suitable for the Hall of Fame. If you are wondering what great movies (and maybe not so great) did NOT make the field, check out the bench-warmers here at March Madness – On the Bench.
At Lilly Library, now that it’s time for The Big Dance –
we hope you join in!
To celebrate Women’s History Month 2018, Lilly Library is shining a spotlight on Women in Sport. Books and movies that feature women athletes are “teeming” in our collections. Come to East Campus and check out this month’s Lilly Collection Spotlight. Click here for the complete line-up.
While you’re at Lilly, visit the exhibit in the foyer, On the Field, the Courts and Beyond: Women in Sports – TITLE IX, that complements our Lilly Collection Spotlight.
Based on the Instagram account @TheUnsungHeroines, a celebration of the pioneering, forgotten female athletes of the twentieth century that features rarely seen photos and new interviews with past and present game changers including Abby Wambach and Cari Champion.
2016 | Sarah Shephard
There’s a battle being fought. It’s raging on the sports fields, in the newsrooms and behind the scenes at every major broadcaster. Women in sport are fighting for equality with more vigour than ever, but are they breaking down the barriers that stand in their way? Sarah Shephard looks behind the headlines to see whether progress is really being made and tells the stories that can no longer be ignored. It’s time for women to switch their focus from the battlefield to the sports field, once and for all.
2007 | Cecil Harris and Larryette Kyle-DeBose
Beginning with the Williams sisters, the authors examine the foundation of their development as tennis phenoms during the 1990s and the prophetic yet unabashed approach of their coach, father, and sports psychologist, Richard Williams, in crafting a world within which they would be groomed to be successful. a compelling examination of the impact of African Americans on the world of professional tennis and the various challenges and outcomes of that involvement.
2015 | Nicholas ChareFILMS
An overview of films about women in sport and a timely critical analysis of their role in shaping perceptions of female athletic ability. It examines themes of aggression, beauty, class, ethnicity, physical feminism, sexuality, synaesthesia and technology in relation to mainstream and arthouse cinematic depictions of sportswomen from Pumping Iron 2 to Bend it Like Beckham.
2004 | Bruce Schoenfeld
50 years ago when Gibson and Buxton were two of the top women’s tennis players in the world. Coming from widely divergent backgrounds (Gibson from a poor black family in Harlem, Buxton from a well-to-do Jewish family in London), the two hooked up in the mid-1950s and became tennis partners and lifelong friends.
2015 | ed. Alex Channon
Offers a wide-reaching overview of current academic research on women’s participation in combat sports within a wide range of different national and trans-national contexts, detailing many of the struggles and opportunities experienced by women at various levels of engagement within sports such as boxing, wrestling and mixed martial arts.
During the 2006 Iran-Bahrain match, the Tehran soccer stadium roars with 100,000 cheering men and, officially, no women. According to Islamic custom, women are not permitted to watch or participate in men’s sports. Many of the ambitious young female fans who manage to sneak into the arena are caught and sent to a holding pen, guarded by male soldiers their own age. Duty makes these young men and women adversaries, but duty can’t overcome their shared dreams, their mutual attraction, and ultimately their overriding sense of national pride and humanity.
DVD 21482 and Streaming Video
Examines the post Title IX media environment in terms of the representation of female athletes. It demonstrates that while men’s identities in sports are equated with deeply held values of courage, strength and endurance, the accomplishments of female athletes are framed very differently and in much more stereotypical ways.
DVD 11362
A promising hurdler, played by Mariel Hemingway, finds needed emotional and athletic seasoning with a caring mentor. After the two fall in love, their relationship is threatened as both vie for a spot on the U.S. Olympic team.
DVD 25223 and streaming video
Members of the Cuban National Women’s Baseball Team discuss their passion for the sport and hardships they faced in Cuba’s society filled with machismo, prejudice and daily hardships.
DVD 6270
The story of the surviving members of the Viennese Hakoah sports club women’s swim team, a world-dominating competitor in the 1930s. The club was eventually shut down during Hitler’s reign, though all the women managed to escape capture. Combines historical footage and contemporary interviews to reconnect the women’s lives and memories.
DVD 5579
The new man in town has just accepted a position as an English professor on a reservation in Utah. Finding it hard to fit in with the Native American community, he decides to take on the challenge of coaching the girls’ basketball team.
DVD 18946
Bliss Cavender is a small-town teenager looking for her own path. Tired of following in her family’s footsteps, she discovers a way to put her life on the fast track–literally. She lands a spot on a roller derby team and becomes “Babe Ruthless.” Co-starring Drew Barrymore in her feature film directorial debut.
Thank you to everyone who enjoyed going out on a Mystery Date With a Book last week! If you didn’t get a chance to check out our display, or if you’re just curious to know what books we selected, here’s a complete list of our mystery picks, along with the library staff member who recommended them. Add them to your Goodreads list. Happy reading!
Selected by Arianne Hartsell-Gundy, Head, Humanities Section and Librarian for Literature and Theater Studies:
Charlotte Brontë, Jane Eyre: “A coming of age story featuring psychic connections, walks on the moors, and a house with a mystery.”
Naomi Novik, Uprooted: “The fairy tale you always wanted as a child…and finally got as an adult.”
Selected by Kim Duckett, Head of Research and Instructional Services:
Anthony Mara, The Tsar of Love and Techno: Stories: “A collection of beautiful interlocking short stories dipping back and forth through 20th century Russia.”
Matthew Kneale, English Passengers: “Twenty narrators tell a fascinating story of Manx smugglers, seekers of the Garden of Eden, and the plight of Tasmanian Aborigines.”
Bruno Schulz, The Street of Crocodiles: “In this little town the real and the imagined blend together in a way you’ve never quite experienced.”
Selected by Brittany Wofford, Coordinator for The Edge and Librarian for the Nicholas School for the Environment:
P. G. Wodehouse, How Right You Are, Jeeves: “For everyone who thought that Carson was the real hero of Downton Abbey.”
Naomi Alderman, The Power: “An electrifying read about gender and power.“
Selected by Elena Feinstein, Head, Natural Sciences and Engineering Section and Librarian for Biological Sciences:
Monique Truong, The Book of Salt: “Flavors, seas, sweat, tears – weaves historical figures into a witty, original tale spanning 1930s Paris and French-colonized Vietnam.”
Audrey Niffenegger, The Time Traveler’s Wife: “According to the author, the themes of the novel are ‘mutants, love, death, amputation, sex, and time.’ Many readers would include loss, romance, and free will.”
Selected by Jodi Psoter, Librarian for Chemistry and Statistical Science:
Amy Butler Greenfield, A Perfect Red: “Empire, espionage, and the quest for the color of desire.”
Stefan Fatsis, Word Freak: “Wonderful word weirdos. Glimpse inside the world of competitive Scrabble.”
Selected by Sarah Park, Librarian for Engineering and Computer Science:
Antoine de Saint-Exupéry, The Little Prince: “It is a love story for the ages.”
Elizabeth Barrett Browning, Sonnets from the Portuguese: “44 different ways to say ‘I love you’ for your valentines.”
Thomas F. Moser with Brad Lemley, Moser: Artistry in Wood: “A story of an extraordinary woodworker who built the furniture in Perkins and Bostock libraries.”
Jeffrey Brown, Darth Vader and son: “We need to take care of our family before conquering the universe. Short and comical.”
Selected by Aaron Welborn, Director of Communications:
Richard Hughes, The Innocent Voyage: “One of the best novels you’ve never heard of. A combination of Peter Pan, Heart of Darkness, and Lord of the Flies, all rolled into one.”
Ryszard Kapuściński, Travels with Herodotus: “ ‘Within every great book there are several others.’ One of those great books, by one of the great world travelers.”
Contributors: Carol Terry, Danette Pachtner and Ira King
Winter Sports: Skiing, Skating and Hockey
Winter Olympics and Sport
Tired of cold wintry weather? Don’t be snowboard – curlup with interesting reading, or peakat these films … what do you have to luge? (Are we skatingon thin ice here?)
If you are ready for vicarious international adventures in spectacular snow and ice, Lilly Library’s collections will transport you. Our latest Collection Spotlight shines on winter sports, Olympic history and snowy landscapes inspired by the upcoming Winter Olympics in PyeongChang, South Korea. Some winning titles are featured below, but judge for yourself and see the full list in Best in Snow.
Film
The Price of Gold (2014, dir. Nanette Burstein) ESPN 30 for 30
The world couldn’t keep its eyes off two athletes at the 1994 Winter Games in Lillehammer – Nancy Kerrigan, the elegant brunette and Tonya Harding, the feisty blonde who would stop at nothing to get on the Olympic podium.
Sister (2012, dir. Ursula Meir)
Sister-Lilly DVD 27001
A drama set at a Swiss ski resort and centered on a boy who supports his sister by stealing from wealthy guests.
Curling (2010, dir. Denis Côté)
On the fringe of society in a remote part of the French-Canadian countryside, the fragile relationship and unusual private life of a father and daughter is jeopardized by dreary, unforeseen circumstances.
Of Miracles and Men (2009, dir. Jonathan Hock) ESPN 30 for 30
The story of one of the greatest upsets in sports history has been told. Or has it? On a Friday evening in Lake Placid, a plucky band of American collegians stunned the vaunted Soviet national team, 4-3 in the medal round of the 1980 Winter Olympic hockey competition. Americans couldn’t help but believe in miracles that night, and when the members of Team USA won the gold medal two days later, they became one for the ages. But there was another, unchronicled side to the “Miracle On Ice.”
Blades of Glory (2007, dirs. Josh Gordon and Will Speck)
Cool Runnings Lilly DVD 7974
In 2002, two rival Olympic ice skaters were stripped of their gold medals and permanently banned from men’s single competition. Presently, however, they’ve found a loophole that will allow them to qualify as a pairs team.
Cool Runnings (1998, dir. Jon Turteltaub)When a Jamaican sprinter is disqualified from the Olympic Games,he enlists the help of a dishonored coach to start the first Jamaican Bobsled Team.
In the 1930s, as the world hurtled towards terrible global conflict, speed was all the rage. Exotic, exciting and above all dangerous, it was by far the most popular event at the Lake Placid Winter Olympics. It required an abundance of skill and bravery. And the four men who triumphed at those Games lived the most extraordinary lives.
Artistic Impressions: Figure Skating, Masculinity, and the Limits of Sport by Mary Louise Adams
In contemporary North America, figure skating ranks among the most ‘feminine’ of sports and few boys take it up for fear of being labelled effeminate or gay. Yet figure skating was once an exclusively male pastime – women did not skate in significant numbers until the late 1800s, at least a century after the founding of the first skating club. Only in the 1930s did figure skating begin to acquire its feminine image.
Roland Huntford’s brilliant history begins 20,000 years ago in the last ice age on the icy tundra of an unformed earth. Man is a travelling animal, and on these icy slopes skiing began as a means of survival. In polar exploration, skiing changed the course of history. Elsewhere, in war and peace, it has done so too.
So many more books and films examine the Olympics from a range of perspectives – from pure sport and Olympic ideals to international political and social concerns and controversies. Explore further in our Collection Spotlight, and visit Best in Snow.
Contributed by Heather Martin, Librarian for African and African American Studies
What is African literature? Is it literature created by Africans or about Africans? These are some of the questions students in the Duke Africa Conversations Club hope to spark in their selection of books for Duke University Libraries’ current Collection Spotlight on Contemporary African Literature.
The Africa Conversations Club encourages discourse at Duke about issues relating to the African continent and the African diaspora. Their selections (chosen in consultation with Heather Martin, African and African American Studies Librarian) highlight contemporary African fiction, nonfiction, and poetry.
Join Africa Conversations for a discussion of “African Literature and Its Place in Academia” with Dr. Tsitsi Jaji, Associate Professor of English at Duke, on Wednesday, January 31, 4:00-5:00 p.m. in Rubenstein Library 153 (Holsti-Anderson Family Assembly Room).
The Contemporary African Literature display will end in February, but books chosen for the display are available in the Duke Libraries any time.
Duke Self-Checkout is a fast, easy way to check out books from the Duke University Libraries.
Starting this week, you can now use your smartphone to check out library books in Perkins and Bostock Libraries, without having to bring them to the desk on the main floor.
Make sure to let Duke Self-Checkout access your camera, send you notifications, and use your location.
Open the app and log in with your Duke NetID and password. Click the ‘+’ sign in the top right corner to activate your camera.
When you find a book you want to check out, use the app on your phone to scan the library barcode. The app will blink green when it recognizes the barcode and check the item out to you right there. That’s it!
Remember to demagnetize your book before you leave the building!
If you want leave the building with your book, make sure you stop at one of the Duke Self-Checkout stations to demagnetize your book so it doesn’t set off an alarm.
Don’t have a phone or don’t want to download the app? Use the iPad at the Duke Self-Checkout stations, located in Perkins near the Perkins / Bostock Lobby, and in Bostock at the Edge Service Desk.
Duke Self-Checkout is also available at the Marine Lab Library.
The end of fall semester is near, and finals exams are even closer. If you feel the need for a little winter holiday cheer or diversion, our librarians can help. With over 30,000 films in our collections, our staff selected 100 holiday-themed films for December’s Lilly Collection Spotlight. There are traditional titles in the list such as A Charlie Brown Christmas, It’s a Wonderful Life, and Home Alone as well as other winter holiday films such as Eight Crazy Nights, Tokyo Godfathers, and Black Candle. Animated classics, international gems, and a few offbeat films such as Bad Santa and A Junky’s Christmas are waiting for you!
Want to see the entire list?
You decide what is Naughty-or-nice-Holiday-films-100 List!
In case you are wondering – yes, we have Santa Claus Conquers the Martians (Lilly DVD 15343)
Don’t want to scroll through one hundred titles? Take a peek at some of our selections and sample the first Video Spotlight on Winter Holiday films in our Video Spotlight Archives.
With the advent of the smartphone and social media platforms like Instagram, photography has suffused our daily lives. You may shoot a pic of the Duke Chapel on the way to an early morning class, take a photo of your lunch at West Union, and get a snapchat vista from your friend on vacation in the mountains. If you’re obsessed with images, we’ve got you covered with this month’s Collection Spotlight at Lilly Library! Check out the wide range of photography books and films on display.
Ansel Adams: 400 Photographs
Adams, whose work was recently featured in an exhibit at the North Carolina Museum of Art, was one of the most celebrated landscape photographers of the Twentieth Century, renowned for his black and white depictions of the stunning scenery of the American West. This book collects photographs from across his multi-decade career. Recommended if you’re craving a reminder of the sublime beauty of the outdoors.
Toy Stories by Gabriele Galimberti
In this unique collection, photographer Gabriele Galimberti traveled around the world photographing children and their toys, spending thirty months on the road and visiting fifty-eight different countries. These striking photographs are fun, but also illuminate the social, economic, and gender issues that surround what toys children grow up with. Recommended if you’re missing your childhood room.
The Beautiful Smile by Nan Goldin
This collection, released on the occasion of Goldin’s 2007 Hasselblad Award, features intimate, diaristic photographs and portraits. Rising to fame as a member and chronicler of the LGBTQ subculture in 1980s and 1990s New York City, Goldin includes both photos from that era and newer works in this book. Recommended if you’re looking for photography that captures both the beauty and fragility of life.
Chromes: 1969-1974 by William Eggleston
One of our personal favorite photographers, Eggleston photographed “ordinary” objects and people around the South and his hometown of Memphis, Tennessee. Eggleston’s work in color helped legitimize the form in a field that was previously dominated by black and white photography. Recommended if you’re a Big Star fan and/or enjoy photos of old gas stations.
And don’t forget that Lilly has a great collection of films you can borrow.
La Jetee (1962)
Since its release in 1962, Chris Marker’s La Jetée has emerged as one of the foundational texts of postwar European cinema. With its rhythmic editing, nostalgic voiceover and parade of black-and-white images, La Jetée exercises a hypnotic effect on its viewers. This short, experimental ‘photo-roman’ stays with you long after its 29 minutes are over.
Lilly DVD 6054
Pecker (1999)
John Waters’ film about a budding Baltimore photographer. Pecker (he got the nickname for pecking at his food as a child) photographs the mundane sights of his Baltimore neighborhood: the hamburger joint where he works, rats making love in the alley behind the diner, the oddball characters in his family, and the dancers in the local lesbian strip club.
Lilly DVD 29861
City of God (2002)
This movie takes place in the favelas or slums of Rio de Janeiro created to isolate the poor people from the city center. They have grown into places teeming with life, color, music and excitement–and with danger. One of the characters, Rocket, obtains a stolen camera that he treasures and takes pictures from his privileged position as a kid on the streets.
Lilly DVD 20755
Our feelings took the pictures: Open Shutters Iraq (2008)
Iraq-born Maysoon Pachachi’s film documents a project in which a group of women refugees from five cities in Iraq living in Syria learn to take photographs and present their lives to each other. Accompanying book is in Perkins Library.
Lilly DVD 26643
Through a lens darkly: black photographers and the emergence of a people (2014)
Filmmaker Thomas Allen Harris offers what he calls a “family memoir” via historical images of African Americans initially through popular and disturbing stereotypes such as those portrayed in D.W. Griffith’s classic 1915 film Birth of a Nation to more realistic and poignant photographs. Using a series of narrative images by African American photographic artists including Anthony Barboza, Hank Willis Thomas, Lorna Simpson, and Gordon Parks, among others, Harris sheds light on a seldom-told aspect of our culture.
As you can see, Lilly Library offers a wide range of books and film about the art, science and history of photography which we hope you will enjoy.
Every year the Duke University Libraries run a series of essay contests recognizing the original research of Duke students and encouraging the use of library resources. We are pleased to announce the winners of our 2016-2017 library writing and research awards.
Recognizing excellence in undergraduate research using sources from the Libraries’ general collections.
Honor Thesis Prize:Anna Mukamal for “Creative Impulse in the Modern Age: The Embodiment of Anxiety in the Early Poetry of T. S. Eliot (1910-1917)”
Third/Fourth-Year Prize:Jack Harrington for “In The Empire’s Back Yard: The Radicalization of Public Opinion In Ireland and It’s Impact on the Anglo-Irish War (1913-1920)”
First/Second-Year Prize:McKenzie Cook for “World War I and The London Theatre”
Recognizing excellence of analysis, research, and writing in the use of primary sources and rare materials held by the Rubenstein Rare Book & Manuscript Library.
Maegan Stanley for “In Honest Affection and Friendlinesse”
Hannah Rogers for “Subversion as Service: The Life and Controversy of Jeanne Audrey Powers”
We will be celebrating our winners and their achievements at a special awards reception coinciding with Duke Family Weekend. All are invited to join us for refreshments and the opportunity to honor the recipients.
Cuban-Americans, the Duke Common Experience and Beyond
Need some new reading material or just interested in seeing what’s in Lilly Library’s collection that you might not know about? Check out Lilly’s Collection Spotlight!
In honor of National Hispanic Heritage Month and the Duke Common Experience Reading Program selection of Richard Blanco’s The Prince of Los Cocuyos, our spotlight shines on books and films relevant to his and the Cuban-American experience. Blanco, the inaugural poet for Barack Obama in 2012, writes in his memoir of his childhood growing up in Miami as a son of Cuban immigrants. The memoir finds Blanco grappling with both his place in America and his sexuality, striving to discover his identity.
Our collections include books on Cuban Art, the Cuban-American immigrant experience in the United States, LGBTQ communities in Hispanic culture, and several books of Blanco’s poetry. Here are a few highlights from our Lilly Collection Spotlight:
Books:
Adios Utopia — Art in Cuba Since 1950
This exhibition catalog covers Cuban art from 1950 to the present viewed through the particular lenses of the Cuban Revolution, utopian ideals, and subsequent Cuban history. The collection covered in this book will be on display at the Walker Art Center in Minneapolis starting in November.
In this book, scholar Frederick Luis Aldama interviews 29 Latinx comic book creators, ranging from the legendary Jaime Hernandez of Love and Rockets fame to lesser known up and coming writers/illustrators.
This bilingual chapbook contains a poem Blanco wrote and read for the reopening of the US Embassy in Havana in 2015. Blanco writes in the opening lines, “The sea doesn’t matter, what matters is this: we all belong to the sea between us, all of us.”
Films:
CubAmerican (2012) DVD 28418
Exploring the causes leading to the exile of millions of Cubans from communist Cuba by depicting the journey of illustrious Cuban-Americans to their new life in the United States
Finally the sea (2007) DVD 12185
“The wreckage of an empty Cuban raft is the catalyst for Tony, a successful Cuban-American businessman, who files from Wall Street to Cuba to discover his roots. His journey develops into a striking love story where politics and romance collide
Mambo Kings (1992) DVD 27116
Musician brothers, Cesar and Nestor, leave Cuba for America (NYC) in the 1950s, with the hopes of making it to the top of the Latin music scene. Cesar is the older brother who serves as the business manager and is a consummate ladies’ man. Nestor is the brooding songwriter, who cannot forget the woman in Cuba who broke his heart. This is an unrated version of the film, with one restored scene.
Visit our Collection Spotlight shelf, in the lobby to the left of the Lilly desk. There are many more titles available to you, and if you want more suggestions – just ask us. Stay tuned – We will highlight our diverse and varied holdings at Lilly with a different theme each month.
This spring Michael Peper and Melanie Sturgeon, two Duke science and engineering librarians, left Duke University Libraries to pursue other opportunities. We’re sad to lose these valued colleagues, but are thrilled to introduce two new staff members and some different roles for remaining staff. Please see below for our updated titles and responsibilities.
Elena Feinstein Head, Natural Sciences and Engineering Section Librarian for Biological Sciences
Elena has moved into a leadership role for the science and engineering librarians group, and she looks forward to continuing her work with the departments of Biology and Evolutionary Anthropology as well as other biologically focused programs.
Ciara Healy Librarian for Psychology & Neuroscience, Mathematics, and Physics
Ciara is thrilled about continuing her work with the Department of Psychology & Neuroscience and Duke Institute for Brain Sciences, and learning more about the needs of the Departments of Mathematics and Physics.
Janil Miller Librarian for Marine Science and Coordinator, Pearse Memorial Library at Duke Marine Laboratory
Janil will continue coordinating library services and collections at the Duke Marine Lab, serving the Nicholas School of the Environment’s Division of Marine Science & Conservation as well as other Marine Lab patrons.
Sarah Park Librarian for Engineering and Computer Science
Sarah joins Duke on July 18 as liaison to the Pratt School of Engineering and the Department of Computer Science. She has 15 years of experience as a science and engineering librarian, most recently at Southern Illinois University Edwardsville. In addition to her library science degrees, Sarah holds an M.S. in applied computer science.
Jodi Psoter Librarian for Chemistry and Statistical Science
Jodi joins Duke on August 14 as liaison to the Departments of Chemistry and Statistical Science. She has 15 years of experience as a science and engineering librarian, most recently at Williams College.
Brittany Wofford Coordinator for the Edge and Librarian for the Nicholas School of the Environment
Brittany will continue to coordinate services and spaces for The Edge research commons and will take on a new role as liaison to the Nicholas School of the Environment. Brittany has experience as the librarian for Cultural Anthropology, which will return to the care of librarian Linda Daniel.
If you’re ever in doubt about which of us to contact, we can all be reached at askscience@duke.edu. We look forward to hearing from you!
A weevil (family Curculionidae), one of many insects on display as part of the of the new Incredible Insects exhibit.
Incredible Insects: A Celebration of Insect Biology
On display June 13 – October 15, 2017
in the Chappell Family Gallery and Stone Family Gallery, Perkins and Rubenstein Libraries, Duke West Campus (Click for map)
Insects are the most numerous and diverse animals on earth. They can be found in almost every environment. Because of their tremendous diversity, they play many important roles in nature, as well as in human society—enchanting us with their beauty, unsettling us with their strangeness. Whether revered or reviled, these fascinating and ubiquitous organisms can truly be said to have conquered the planet.
A new library exhibit offers a glimpse into the multifaceted world of insects, including research on insects conducted here at Duke.
There are three times as many species of insects than all other animals (mammals, birds, fish reptiles, amphibians) combined. The number of individual insects is estimated to be in excess of a quintillion (that’s a 10 with 18 zeros behind it).
The exhibit is divided into several sections, including insect evolution and diversity, coloration and camouflage, types and stages of insect metamorphosis, the roles of insects in human history and culture, and a fascinating look at two of nature’s greatest mysteries: the migration of the monarch butterfly and the clockwork-like appearance of periodical cicadas.
Periodical cicadas are one of the most remarkable phenomena of nature. They suddenly appear in the millions every 13 or 17 years. Then they disappear as suddenly as they came,
Exhibit visitors can also hear sound recordings of insect calls at a nearby kiosk and see up-close images of insects taken with electron microscopes.
Around the corner from the Chappell Family Gallery, viewers can step inside the Rubenstein Library’s Stone Family Gallery and peruse several selections of rare books that complement the exhibit. The exhibit curators selected these works because they represent some of the earliest scientific investigations to discover general aspects of biology and natural history through the study of insects.
Image of a fly drawn by Robert Hooke in his Micrographia (1667), one of several rare historical volumes on entomology on display in the Stone Family Gallery.
Incredible Insects was curated by a team of entymology students, faculty and staff from the Duke biology department.
Lilly Library offers a selection of Full Frame titles
Each spring since 1998, Durham has hosted international filmmakers and film lovers who flock to the Full Frame Documentary Film Festival. Festival goers revel in the latest in documentary, or non-fiction, films which are presented in venues throughout historic downtown Durham.
Because it is the 20th anniversary, this year’s festival’s thematic program is a cinematic retrospective of the twenty years of Full Frame. Curated by Artistic Director Sadie Tillery, notable films, filmmakers, and special moments that have distinguished Full Frame since it was founded in 1998 are to be highlighted this year.
Do you know that Duke University is a major supporter of Full Frame?
Of special note, because of his support and commitment to the arts, Duke University President Richard Brodhead will be honored with the Full Frame 2017 Advocate Award. In addition, the Duke University Libraries support and highlight films from past festivals. If you don’t attend the festival, consider the Libraries’ collections. A major resource is the Rubenstein Library’s Full Frame Archive Film Collection, that includes festival winners from 1998 through 2012. In addition, the film and video collection at Lilly Library on East Campus contains a selection of Full Frame titles available to the Duke community.
The holidays are just around the corner, and you still don’t know what to get that person on your list who has everything. Don’t worry, we’ve got you covered.
Instead of another tie or pair of socks, give a gift that matters to every member of the Duke community. Make an honorary or memorial gift to Duke University Libraries, and make a difference in the lives of our students, faculty, and researchers. Your gift to one of the funds below helps us continue to add resources and services that support the Duke and Durham community.
You can direct your honorary or memorial gift to one or more of the Libraries’ funds, including:
The Library Annual Fund provides flexible, unrestricted support for the Libraries’ varied operational needs (and the Honoring with Books program gives Annual Fund donors who contribute $100 or more the opportunity to recognize a special person or event with an electronic bookplate)
The Adopt-A-Book program funds the conservation of an item from the collections, and provides flexible support for the Conservation Services department
The Adopt-A-Digital Collection program funds the long-term preservation and storage of our digital collections.
Thank you for strengthening the Duke community by making a gift to the Duke University Libraries this holiday season!
PLEASE NOTE: When you make an honorary or memorial gift online, please be sure to fill out the necessary information in the “Gift Dedication” section of our online giving form.
World AIDS Day Event to take place in Rubenstein on November 30, 3-6 pm
The papers of Maria de Bruyn, a medical anthropologist, are a recent acquisition by the History of Medicine Collections and will be the focus of this event and several others this fall. The Duke University History of Medicine Collections is a rich resource for teaching Duke medical students about the centuries of medical experimentation that inform the modern practice of medicine.
On November 30, the Franklin Humanities Institute Health Humanities Lab will host a special World AIDS Day event featuring a keynote address by de Bruyn and a lecture by poet and writer Kelley Swain.
In addition, students in professor Kearsley Stewart’s Duke Global Health Institute’s fall seminar on HIV/AIDS will discuss their three-week workshop with Swain and present an exhibit of their work based on materials from the Maria de Bruyn collection.
A reception is to follow the presentations. The event is free and open to the public and will take place on November 30, 3:00 – 6:00 pm, in Rubenstein Room 153. Contact Kearsley Stewart for more information, k.stewart@duke.edu.
Detail from Latin MS No. 8, David M. Rubenstein Rare Book & Manuscript Library
As bookbagging classes for the Spring semester commences, we are excited to announce the next wave of Archives Alive courses offered for Duke undergraduates. These courses are aimed at enabling students to develop innovative and significant projects based on original materials held in the David M. Rubenstein Rare Book & Manuscript Library.
As opposed to traditional offerings, Archives Alive courses provide students with weekly opportunities to conduct “hands-on” explorations into the rich and varied collections of rare print, manuscript, photographic, and audio materials. Students gain first-hand exposure to advanced research techniques in the new classroom space of the Rubenstein Library.
This upcoming semester, the Rubenstein Library will host two engaging courses that debuted last year. “History of the Book,” a phenomenally successful course on written text in its earliest forms through the 21st century, has been described by students as “thrilling,” “awesome,” and “engaging.” Another course dealing with recording technology, music, local history, and digital tools, “NC Jukebox,” has students raving about the hands-on explorations into century-old correspondence and audio recordings.
These classes for Spring 2017 are listed as follows:
Topics in Digital History & Humanities: NC Jukebox
HISTORY 390S-1/ISS 390S/MUSIC 290S-1
Curriculum Codes: ALP, CZ, R
Thursday 10:05-12:30
Instructors: Trudi Abel/Victoria Szabo
History of the Book
CLST 360/MEDREN 346/ISS 360/HISTORY 367
Curriculum Code: ALP
MW 3:05-4:20. Rubenstein Library 150
Instructor: Clare Woods
In case you can’t get enough of politics in this election cycle, Lilly Library’s exhibit Reel Politics: Focus on Elections highlights the wide range of political or politically themed films in our collections. Duke students, staff and faculty can “write-in” their favorite film or choose from some of the titles represented.
Veep Lilly DVD 26598
Mr. Smith Goes to Washington Lilly DVD 605
The American political process and environment are explored, celebrated and, yes, deplored in all genres of film and television programs: romances, satires, and searing dramas, cynical and sometimes insightful documentaries. Films available in the Lilly Library collections include classics such as Mr. Smith Goes to Washington or its cynical counterpart, The Candidate, idealized romances such as The American President, comedies such as Election, and documentaries such as Weiner or The War Room. Television series also portray the American political scene in a variety of ways – what starker contrast in depictions of the Presidency can be found than between that of The West Wing and the recent series, House of Cards?
What are the bestfilms , documentaries and television series about American elections? The films and television series in the exhibit represent just a very few of the hundreds of films and series about American elections and politics that the library offers. Explore the possibilities with a search of our library catalogue, peruse the Lilly Video Spotlight on Political Documentaries, and remember, just like the candidates, films have their champions and detractors.
In keeping with the season, perhaps you can conduct your own poll!
Reel Politics: Focus on Elections Exhibit on display through October Lilly Library foyer
The treasures of Duke’s branch libraries are often hidden. The circulating collections and services of these smaller libraries often claim the pride of place. Both libraries on East Campus, Lilly Library and Music Library, however, hold precious material relating to their subject collections. Known in the library world as “medium rare” (as opposed to the rare materials located in the David M. Rubenstein Library) such primary source materials allow students to examine history first hand.
This fall the Lilly Library added a lobby display case to highlight its unique collections. The inaugural display is one volume of our three-volume Vitruvius Britannicus, a large and early folio devoted to the great buildings of England to be seen in 1717.
Vitruvius Britannicus
An outstanding example of a folio (book) format as well as the awakening of interest in British architecture by its own architects – quoting from the Oxford Art Online – Vitruvius Britannicus was a cooperative venture that appears to have developed out of the desire of a group of booksellers to capitalize on an already established taste for topographical illustration.
Published in 1715 and 1717, the two original volumes each consisted of 100 large folio plates of plans, elevations and sections chiefly illustrating contemporary secular buildings. Many of these plates provided lavish illustration of the best-known houses of the day, such as Chatsworth, Derbys, or Blenheim Palace, Oxon, intended to appeal to the widespread desire for prints of such buildings as well as providing their architects a chance to publicize their current work.
We invite you to visit the Lilly Library on East Campus and to enjoy this “medium rare” folio on exhibit. For more information about the Lilly Library folio or art and image collections, contact Lee Sorensen, the Librarian for Visual Studies.
Exhibits in the Mary Duke Biddle Room (shown here) in the Rubenstein Library will be open on Saturday for Duke Homecoming weekend.
The Rubenstein Library exhibit suite (Mary Duke Biddle Room, Stone Family Gallery, and Josiah C. Trent History of Medicine Room) will all be open on Saturday, October 1, from 1:00 p.m. to 5:00 p.m., for Duke Homecoming weekend.
Library visitors can see Virginia Woolf’s writing desk, a copy of the Bay Psalm Book (first book printed in what is now the United States), two of our double-elephant folios of Audubon’s Birds of America, and many other treasures from the Rubenstein Library.
Starting this semester (Fall 2016), the Duke University Libraries will be piloting a program to provide selected textbooks on 3-hour reserve in Perkins Library on West Campus. Some textbooks will also be available at Lilly Library on East Campus.
Included among the 300 items are textbooks for courses in Economics, Chemistry, Math, Latin, French, Italian, and Spanish. The books have been selected based on orders placed with the Duke Textbook Store by departments and faculty.
Please note:Textbooks on reserve are not intended to take the place of students purchasing textbooks for their courses. Due to budget limitations, the Libraries are unable to purchase textbooks for every course at Duke.
Circulation numbers will be reviewed to determine if this pilot program is valued and should be extended.
For questions related to textbook reserves at Perkins Library, please contact: perkins-reserves@duke.edu.
For questions related to textbook reserves at Lilly Library, please contact: lilly-requests@duke.edu
Learn to “swim” – and to keep swimming – in the Libraries!
The Libraries welcome the newest Blue Devils
On East Campus, after students settle in and begin classes, the Lilly Library and Duke Music Library offer several ways for the newest Blue Devils to learn and benefit from the incredible resources of the Duke Libraries. Lilly and Music sponsor Library Orientation events – including a film on the East Campus Quad and an Open House to introduce students to library services and collections. In recent years, students ventured into a library-themed Jurassic Park, played The Library Games, and were wowed by theIncredibles and our libraries’ super powers. This year, the Class of 2020 will explore the power of discovery and the rewards of research, and learn to “keep swimming” in our resources when they …
Dive Into the Libraries
Schedule of Library Orientation Events for Fall Semester 2016
After the excitement of the beginning of the new semester subsides, the Duke University Libraries continue to reach out to our students, always ready to offer research support and access to resources in support of their scholarly needs.
Here’s to a great fall semester!
Keep swimming! And, remember – we’re available to help you “keep searching”!
Thanks to Devils After Dark for partnering
with the East Campus Libraries for our orientation events.
Frank C. Brown in the field, date and location unknown. Brown often used a car battery to power the recording devices he used.
We are a nation linked by iHeartRadio stations playing “Start Me Up” by the Rolling Stones—that much is certain. I come to understand this as I drive the Frank Clyde Brown Collection’s 60 wax cylinders and 76 aluminum discs of folk songs and ballads to the Northeast Document Conservation Center (NEDCC) in Andover, Massachusetts. There, the NEDCC will use a new and highly innovative technology called IRENE to help us rediscover these performances, which have been essentially unavailable to scholars for nearly a century.
It’s almost too easy to contrast that single, frequently repeated song (unloved by me) with my cargo, but I do it anyway: it’s a 15-hour trip and I’ve got time. The 136 cylinders and discs hold an estimated 1,367 performances collected by Brown as he traveled across North Carolina between 1915 and his death in 1943. Brown, an English professor who also served as comptroller during Trinity College’s transition into Duke University, somehow also found time to drive into back areas throughout North Carolina to record this music. There’s a certain symmetry to me driving his recordings from Duke to Andover.
Because they are too fragile to be played as intended, the cylinders and discs will be digitized using a non-contact visual scanning technology known as IRENE. Image courtesy of NEDCC.org.
The wax cylinders are especially brittle, though, which is why Craig Breaden and I finally decided I should drive them to the NEDCC rather than ship them. Craig, the Rubenstein Library’s Audiovisual Archivist, serves as the Project Manager for this grant. We’ve taken special care in packing, and each cylinder is stored in its own box. Twenty cylinders are then housed in a storage box, and for the trip, each storage box is packed in a larger box and surrounded by foam packing peanuts. The single storage box of aluminum discs is packed the same way. Although not as fragile as the wax cylinders, some of the discs use an acetate “lacquer” for the recording medium, which can be damaged.
The care extends to the trip: I’ve rented a minivan, which provides the bonus of a separate air conditioning system for the back storage area. That helps keep the cargo at a uniform temperature—changes in temperature are particularly hard on wax cylinders. In fact, I decide not to eat dinner while the outdoor temperature is above 75 degrees because I don’t want to leave the air conditioning off for too long. I drive to Hartford, Connecticut, that night and when I check into the motel, I take all four boxes into my room, where I put them on the bed instead of on the floor, just in case the fan coil unit leaks. They look kind of cozy there.
The boxed-up cylinders and discs, resting from their journey.
What makes the IRENE technology worth the trouble? Craig and I will write more about it over the course of this project, but IRENE is perfect for material like this. IRENE makes ultra-high resolution visual scans of a disc’s or cylinder’s grooves to create an image of the track; its software converts the images to sound files. Creating visual scans first means that we can get an accurate digital sound file without a needle or stylus. That provides two important advantages: we don’t risk further damage to the grooves of these fragile media, and IRENE can sometimes recover sound from cracked or broken discs and cylinders if it can get an image of the grooves sufficient to match up with the other pieces. It’s amazing, and only the NEDCC provides this service.
Jane Pipik, Manager of Audio Preservation Services at NEDCC, demonstrates how IRENE translates visual groove scans into digital sound files.
All of us associated with this project feel like the Brown Collection is a great collection, the music a treasure waiting to be rediscovered. The recordings contain ballads and folk songs that can be traced back to England, songs that traveled to North Carolina from other parts of the United States, and songs like those around the murder of Laura Foster by Tom Dula (a.k.a. Tom Dooley) that originated here.
And that’s what distinguishes this music from the Stones’ “Start Me Up.” Although the same song might be represented several times in the collection, each performance is unique; each musician provided his or her own take on the lyrics and music, or of the people from whom he or she learned the music. Even though the title might be the same, each performance potentially offers insights to us about the culture of the musicians’ locale. That is what makes the trip worth it.
The grant to digitize Frank Clyde Brown’s recordings is part of the Council on Library and Information Resources’ Digitizing Hidden Special Collections and Archives awards program, a national competition that funds the digitization of rare and unique content held by libraries and cultural memory institutions and that would otherwise be unavailable to the public. The Council on Library and Information Resources is an independent, nonprofit organization that forges strategies to enhance research, teaching, and learning environments in collaboration with libraries, cultural institutions, and communities of higher learning.
The program receives generous support from The Andrew W. Mellon Foundation. Founded in 1969, the Andrew W. Mellon Foundation endeavors to strengthen, promote, and, where necessary, defend the contributions of the humanities and the arts to human flourishing and to the well-being of diverse and democratic societies by supporting exemplary institutions of higher education and culture as they renew and provide access to an invaluable heritage of ambitious, path-breaking work. Additional information is available at mellon.org.
Exhibits in the Trent History of Medicine Room (shown here), Mary Duke Biddle Room, and Stone Family Gallery in the Rubenstein Library will all be open on Saturday for Duke Commencement weekend.
The Rubenstein Library exhibit suite (Mary Duke Biddle Room, Stone Family Gallery, and Josiah C. Trent History of Medicine Room) will all be open on Saturday, May 14, from 9:00 a.m. to 5:00 p.m., for Duke Commencement weekend.
Library visitors can see Virginia Woolf’s writing desk, a copy of the Bay Psalm Book (first book printed in what is now the United States), our double-elephant folios of Audubon’s Birds of America, and many other treasures from the Rubenstein Library.
The paradoxes of time travel are a never ending source of fascination for sci-fi film buffs. Lilly’s robust collection includes a few lesser known, but intriguing examples. In Timecrimes (2007) a man is drawn to a young woman who appears mysteriously in the woods near his house. The resulting events pull him into a series of time loops.
Primer (2004), which won the Grand Jury Prize at Sundance, is the tale of two men who invent a rudimentary time travel device in their garage. The Navigator (1988) tells the story of a band of 14th century townsfolk who, while trying to escape the Black Death, stumble upon a fissure in time and end up in the 20th century. Jacques Rivette’s Celine and Julie Go Boating follows the evolving friendship of two women and their magical trip into the past as they attempt to rescue a young girl.
Explore the Duke Libraries film and video collection for more time travel-related titles.
In the mid 1980s Spike Lee opened the door for many African-American filmmakers. It is sometimes easy to forget those who laid the groundwork for his success. Ivan Dixon’s 1973 film The Spook Who Sat by the Door takes a look at discrimination within the CIA. Haile Gerima, the first important African-American female director, gave us Bush Mama (1975), which details the difficult life of a single mother.
Past Full Frame entries available at Lilly Library
It’s that time of year again!
Each spring, international filmmakers and film lovers flock to the Full Frame Documentary Film Festivalto experience the latest in documentary, or non-fiction, cinema showcased in our very own historic downtown Durham. Film showings highlight new programming in competition, and other events include expert panel discussions and themed screenings. Tickets go on sale April 1st.
Duke University Libraries support and highlight films from past festivals. One resource is the Full Frame Archive Film Collection, that includes festival winners from 1998-2012. The film and video collection at Lilly Library includes many more Full Frame titles available to the Duke community.
Full Frame 2015 exhibit
This year’s 19th Annual Full Frame Documentary Film Festival honors independent director and documentary cinematographer, Kirsten Johnson, with the 2016 Tribute Award. Cameraperson, Johnson’s newest film, will be screened and a retrospective of her work will be presented. This year’s Thematic Program is a series titled “Perfect and Otherwise: Documenting American Politics,” curated by filmmaker R.J. Cutler, known for such films as The War Room and The World According to Dick Cheney.
When: April 7-10, 2016
Where: Various venues in Downtown Durham
The festival is a program of the Center for Documentary Studies and receives support from corporate sponsors, private foundations and individual donors whose generosity provides the foundation that makes the event possible. The Presenting Sponsor of the Festival is Duke University.
Palfrey is the author of “BiblioTech: Why Libraries Matter More than Ever in the Age of Google”
What: Lecture and Opening of the Barbaralee Diamonstein-Spielvogel Archive When: Thursday, April 7, 5:00 p.m. Where: Holsti-Anderson Family Assembly Room, Rubenstein Library Reception to follow
Join the Duke University Libraries as we celebrate the opening of the Barbaralee Diamonstein-Spielvogel Archive with a special lecture featuring educator and technology expert John Palfrey, distinguished authority on education and technology and author of BiblioTech: Why Libraries Matter More Than Ever in the Age of Google (Basic Books, 2015).
Palfrey is the Head of School at Phillips Academy in Andover, Massachusetts. He is also a faculty co-director of the Berkman Center for Internet & Society at Harvard University. Previously, Palfrey served as Vice Dean for Library and Information Resources at Harvard Law School and as the founding chairman of the Digital Public Library of America. He has written extensively on internet law, intellectual property, and the potential of new technologies to strengthen democracies locally and around the world.
Palfrey’s talk will be followed by a brief response by N. Katherine Hayles, James B. Duke Professor of Literature at Duke and author of numerous books, including How We Think: Digital Media and Contemporary Technogenesis (University of Chicago, 2012).
Sponsored by the Duke University Libraries, David M. Rubenstein Rare Book & Manuscript Library, Information Science + Studies Program, Information Initiative at Duke, Masters of Fine Arts in Experimental and Documentary Studies Program, Center for Documentary Studies, Forum for Scholars and Publics, and the UNC School of Information and Library Science.
It’s Women’s History Month! Spend this March 2016 watching wonderful films created by talented women from around the world.
The Video Spotlight on Women Filmmakers, created by Lilly Library’s own audio-visual specialist and film aficionado, Ken Wetherington, can give you great ideas of where to start.
In recent years women in film have begun to be slightly better recognized, like Katheryn Bigelow’s oscar-winning direction (the only time for a woman!) of The Hurt Locker.
But did you know that in the early days of cinema, many women were powerful creative forces? Movies like Lois Weber’s Suspense, The Ocean Waifby Alice Guy Blaché and Cleo Madison’s Eleanor’s Catch,and other women pioneers of early cinema, can be viewed in Duke Libraries’ new subscription database, Kanopy Streaming Video.
Check out Lilly’s foyer display exhibiting films by women in the history of cinema. Some of the titles just may surprise you…
Some 60 wax cylinders and 76 aluminum discs containing approximately 1,367 songs recorded in the 1920s and 1930s will be digitized as part of the project.
The collection includes some 1,367 songs recorded in the 1920s and 1930s on wax cylinders and aluminum discs. The recordings were made in the field by folklorist, professor of English, and Duke University administrator Frank Clyde Brown (1870-1943), who traveled across North Carolina collecting folk songs, sayings, stories, and other folklore between 1912 and his death in 1943. Brown collected songs from at least 52 of North Carolina’s 100 counties, representing all regions of the state.
“The recordings include music unique to North Carolina, as well as popular American folk songs, traditional British ballads, and a range of other tunes,” said Winston Atkins, Preservation Officer for Duke University Libraries and the principal investigator for the project. “Taken together, they represent an important and untapped primary source of American folk music in the early twentieth century.”
The songs have never been widely accessible due to the age and fragility of the recording technology Brown used, as well as the difficulty of transferring them to more modern media formats.
Because they are too fragile to be played as intended, the cylinders and discs will be digitized using a non-contact visual scanning technology known as IRENE.
“Until recently, there has been no non-destructive way to recover audio on historical wax cylinders and aluminum discs, which require a mechanical stylus and can be damaged if played today,” said Craig Breaden, Audiovisual Archivist in Duke’s David M. Rubenstein Rare Book & Manuscript Library.
The Duke recordings will be digitized using a new non-contact technology, known as IRENE, at the Northeast Document Conservation Center in Andover, Massachusetts. IRENE takes ultra-high resolution visual scans of the grooves imprinted on the cylinders and discs and mathematically translates those into digital sound files that are remarkably faithful to the original recordings. Because there is no actual contact with the recording, IRENE’s scans can also capture sounds from damaged media.
Digitization will begin in the summer of 2016 and take approximately one year. The recordings will then be described and processed, and the collection will be made freely and publicly available through the Duke University Libraries website in 2018.
Undated photograph of Frank C. Brown from the Duke University Archives.
Born in 1870, Frank Clyde Brown began his career as a professor of English at Trinity College in Durham (the forerunner of Duke University) in 1909 and later became chairman of the department. Between 1924 and 1930, as Trinity expanded into Duke University, Brown served as the institution’s first comptroller, overseeing the construction of West Campus and the renovation of East Campus. He also served as university marshal, entertaining distinguished visitors to the new university.
In 1913, at the urging of legendary folklorist and musicologist John A. Lomax, Brown founded the North Carolina Folklore Society and was elected its first president. He later served as its secretary-treasurer, program chairman, and primary collector until his death in 1943. His efforts to record the sounds and nuances of North Carolina’s “folk” were part of a national trend in the early twentieth century to preserve American folk culture, aided by new technologies that allowed folklorists to make recordings in the field. The 1,367 songs captured by Brown are a significant part of that legacy.
The seven-volume Frank C. Brown Collection of North Carolina Folklore, published posthumously by Duke University Press between 1952 and 1964, represents Brown’s lifetime of collecting. It is widely regarded as one of the premiere collections of American folklore ever published and is available online. Four of the seven volumes are dedicated to the music Brown recorded and include transcribed melodies and song lyrics. However, the editors of Brown’s work left out an estimated 400 songs he recorded. These “bonus tracks,” which are found on the wax cylinders and aluminum discs but not in the published collection, will be digitized as part of the project.
“All Day Singing.” Woodcut by Clare Leighton, from Vol. 2 of the Frank C. Brown Collection of North Carolina Folklore, published by Duke University Press in 1952.
Brown’s original manuscripts and notes, which were used to compile the collection, along with his original recordings, are housed in Duke’s Rubenstein Library.
In 2015, two Duke faculty members—Victoria Szabo and Trudi Abel—incorporated some of the Frank C. Brown recordings into NC Jukebox, an interdisciplinary Bass Connections course introducing undergraduate and graduate students to digital history. Students conducted original research on the history of the recordings and tracked down the descendants of some of the singers and musicians. The course will be offered again in Spring 2017.
The grant to digitize Brown’s recordings is part of CLIR’s Digitizing Hidden Special Collections and Archives awards program, a national competition that funds the digitization of rare and unique content held by libraries and cultural memory institutions that would otherwise be unavailable to the public.
Getting ready for Halloween? So is Lilly Library! Come check out our collection of spooky DVDs and graphic novels, on exhibit through the end of October.
The H Word: Horror in the Libraries
Future Imperfect: Dystopian and Post-Holocaust Cinema
The term “Hackathon” traditionally refers to an event in which computer programmers collaborate intensively on software projects. But Duke University Libraries and the History Department are putting a historical twist on their approach to the Hackathon phenomenon. In this case, the History Hackathon is a contest for undergraduate student teams to research, collaborate, and create projects inspired by the resources available in the David M. Rubenstein Rare Book and Manuscript Library collections. Projects may include performances, essays, websites, infographics, lectures, podcasts, and more. A panel of experts will serve as judges and rank the top three teams. Cash Prizes will be awarded to the winning teams.
Join the Duke University Libraries for a night of comics-themed trivia at Fullsteam Brewery in downtown Durham. Test your knowledge of superheroes, women in comics, comics and war, popular media depictions of comics, and more.
Duke’s Rubenstein Library is home to the Edwin and Terry Murray Comic Book Collection, which includes over 65,000 comics from the 1930s to the present, making it one of the largest archival comic collections in the world.
Our comics trivia night will take place at Fullsteam Brewery in downtown Durham on July 23.
Our comics trivia night will coincide with Durham Comics Fest on July 25, an annual, all-ages celebration of comics and graphic novels organized by the Durham County Library.
This event is free and open to the public, ages 21 and up.
The 2015 season of the American Dance Festival has now kicked off with fabulous performances through July 25th.
To help you get your groove on, check out dance-themed highlights from Lilly Library’s film/video collection in the Lilly Video Spotlight: Dance on Film.
If our spotlight whets your appetite, explore Lilly Library’s large selection of dance DVDs to keep you tripping the light fantastic all summer long. Don’t feel like tripping the light fantastic with Lilly? The ADF Archives serve as an excellent resource for dance historians, and this summer the International Screendance Festival hosts screenings at the Nasher Museum of Art.
Updated from a June 2014 post authored by Danette Pachtner, Librarian for Film, Video & Digital Media and Women’s Studies
The concept of cloning raises ethical issues, especially as it grows more feasible than fictional. The popularity of the current television series Orphan Black (yes, we have it!) helps to shine a spotlight on this issue. Cloning, as a theme in film, makes for compelling, thoughtful and entertaining viewing. We invite you to check out some of these films in Lilly Library’s DVD collection which explore the implications of cloning .
Moon – DVD 17687
Moon (2009), a compelling and suspenseful film, follows an astronaut running a solo mining operation. When an accident triggers a series of inexplicable events he begins to doubt the real purpose of his mission. The film is a textbook example of how to make a thoughtful and good-looking sci-fi thriller on a low budget.
Never Let Me Go(2010) poses an alternate history in which clones are used for organ replacements for “originals.” This powerful and moving film follows three “donors” from childhood into their twenties.
When a person is cloned, what happens to his soul? The Clone Returns Home (2009) addresses life, death, love, and family. Those with patience will be rewarded with this deliberate, meditative film from director Kanji Nakajima.
And for those who prefer action, there’s always Star Trek: Nemesis(2002).
Steve Roden and Dan Goodsell. Krazy Kids’ Food: Vintage Food Graphics. Los Angeles: Taschen, 2003.
Steve Roden, sound artist, painter, writer, and collector is in residence at Duke Rubenstein Library this month. Throughout the month he’s giving talks, performances and demonstrations at various Duke and Durham venues. Whether you get a chance to hear Roden’s talks and pieces, his publications are well supported at Duke’s Lilly (art) and Music libraries.
Most engaging, perhaps, is his 2003 collection of retro advertisements for children’s products, Krazy Kids’ Food. A retrospective of his work,Steve Roden in Between : a 20 Year Survey, is in the Lilly Library. More aurally inclined? Check out (literally!) Roden’s sound recording, Splitting Bits, Closing Loops, a CD at the Music Library. Somewhere in between? We recommend his edited book, Site of Sound : of Architecture and the Ear, exploring the relationship between sound, language, orality and hearing with writings on Vito Acconci, Steve McCaffery, Achim Wollscheid, GX Jupitter Larsen, and Marina Abramovic.
Starting Oct. 1, Duke students, faculty, and staff will be able to check out books in-person from nearly a dozen other major research libraries.
Duke University students, faculty, and staff will soon enjoy on-site library borrowing privileges at several other major research universities, courtesy of a new program known as BorrowDirect Plus.
Under a new pilot agreement beginning October 1, 2014, students, faculty, and staff from the following institutions will have reciprocal on-site borrowing privileges: Brown University, University of Chicago, Columbia University, Cornell University, Dartmouth College, Duke University, Harvard University, Johns Hopkins University, Massachusetts Institute of Technology, University of Pennsylvania, Princeton University, and Yale University.
Guest users who have been verified and have home library accounts in good standing will have in-person access to materials at any of the participating libraries. When visiting one of these libraries, members of the BorrowDirect Plus community will need to show their campus ID card and log into their home library account to show their current status. Once verified, they will be issued a library card from the institution they are visiting.
Items, collections, and participating libraries available will vary by institution. The lending library’s policies and loan periods apply to guest borrowers, and it is recommended that users considering a visit to another library view their policies ahead of time. Borrowed items may be returned at either the lending library or the user’s home library. (For example, a book checked out at Yale could be returned here at Duke, and vice versa.)
For the most part, these same materials are already available through BorrowDirect, a rapid book request and delivery system used by all of the participating institutions (with the exception of Duke). The new agreement expands the system to include this in-person component.
Just a sampling of the hundreds of popular titles you can now download as eBooks or audiobooks and enjoy on your own device. Click on the image to get started.
Duke University Libraries and Ford Library at the Fuqua School of Business are excited to offer a new service that allows library users to download and enjoy popular eBooks and audiobooks on their own devices, including iPhones, iPads, NOOKs, Android phones and tablets, and Kindles.
The new service, called OverDrive, has hundreds of popular fiction and non-fiction titles to choose from, including best-selling novels, well-known classics, self-improvement guides, and much more. We are adding new titles to Duke’s collection all the time.
Here’s how it works:
To get started, visit the Duke OverDrive website. (You can easily get there through the eBooks portal on our library website.)
Browse through the available titles, and check them out using your Duke NetID.
You can check out up to five (5) eBooks or audiobooks at one time.
Titles will automatically expire at the end of the lending period (21 days). There are no late fees!
eBooks can be read immediately on any device with an internet browser. Audiobooks can be streamed using the OverDrive Media Console app, which you can download for free on all major desktop and mobile platforms.
If a title is already checked out, you can place it on hold and request to be notified when it becomes available. You can place up to ten (10) titles on hold at a time.
If you don’t see a title you’re looking for, submit a request from any search page using the option. We’ll add requested titles to our wishlist and purchase them as funds become available.
Once you download a title, you can transfer it to your iPhone, iPad, NOOK, Android phone or tablet, or Kindle.
That’s it! Pretty simple.
In addition to hundreds of new and recently published books, you can also download tens of thousands of public domain classics as eBooks through OverDrive. Look for the “Project Gutenberg” link under Featured Collections.
We are in the process of adding to our initial selections in OverDrive, so we encourage you to submit recommendations through the site if there are eBooks or audiobooks you’d like to see available.
Screenshot of the OverDrive interface. Just a click “Borrow” to check out a title with your Duke NetID, or place it on hold and get notified when it becomes available.
We’re looking for undergraduates, graduate students, and faculty to participate in one-hour focus groups.
Your opinion counts! Share your thoughts about ways to improve and enhance library services, collections, and spaces in a one-hour moderated focus group. In return, we’ll feed you!
Here in the Libraries, we’re always trying to up our game. To help us serve our Duke students and faculty better, we conduct periodic focus groups with undergraduates, graduate students, and faculty members.
Your opinion counts! Share your input and make a difference. Focus groups help us improve our existing services and develop new ones to meet emerging needs. Click on the links below to be part of a focus group session.
Focus Groups for Undergraduates
Session 1: Tuesday, April 8, 6-7 p.m., Perkins 118 Catered dinner from Armadillo Grill Sign up for this focus group
Lilly Library has great films featuring action heroines. Go ahead, make her day –
Check out these heroines and their sisters in action in the Lilly Video Spotlight!
La Femme Nikita (1990)
La Femme Nikita (DVD 8982) A cop-killer junkie (Anne Parillaud) is forced by the government to become an undercover assassin or face a life in prison.
Brave (DVD 22979) Princess Merida, an archer and self-reliant young woman, makes a decision which defies custom and brings chaos to her kingdom. To restore her kingdom, she must discover her bravery and inner strength.
Alien (DVD 3311) Terror begins when the crew of a spaceship investigates a transmission from a desolate planet and discovers a life form that is perfectly evolved to annihilate mankind.
Guest post by Kathryn Desplanque, a third-year Ph.D. student inArt, Art History & Visual Studies. Her work focuses on satirical etchings and engravings in late eighteenth-century and early nineteenth-century France. This semester she taught a Writing 101 class on modern caricature.
Students arranging artwork for the Student Wall exhibit. Photo courtesy of Kathryn Desplanque.
In my Writing 101 class, “Laughing Matters: Interpreting and Contextualizing Modern Caricature,” I wanted to give my students a chance to interact with the rich cartoon periodical collection of Perkins Library and the Rubenstein Rare Book & Manuscript Library. The cartoon periodicals contained therein, of which my students were particularly drawn to the American Puck and the British Punch,contain gorgeous chromolithographed or woodblock engraved caricatures. These complicated visual objects necessitate interdisciplinary research, and through them, I have encouraged my students to engage with the material history of print culture and the periodical press.
I also wanted to give my students an opportunity to explore a kind of writing which I personally find to be tremendously challenging: writing and curating for public audiences. To prepare our Perkins Student Wall exhibit, the students of W101 “Laughing Matters” reverse-engineered genre guidelines for label writing, produced magnificent labels, curated and hung our exhibit, Reading Between the Lines: Comical Interpretations of the Nineteenth Century. They did all of this with careful attention to audience experience: they built sub-themes into our exhibit, and hung the caricatures so as to take advantage of the colors and perspectival lines of their pieces. Throughout the curatorial process, I feel like I’ve learned the most of all, thanks to the candid and insightful discussion we’ve had throughout the semester.
Check out the exhibit!Reading Between the Lines will remain up on the Student Wall on the first floor of Perkins Library through the end of the fall 2013 semester.
Halloween always brings out the worst in people. Garish pumpkin sweaters and sequined Walmart costumes. It was with that dejection about this commercial holiday that I discovered the ghost stories of a prominent art historian, the Cambridge manuscript curator Montague Rhodes James http://www.dictionaryofarthistorians.org/jamesm.htm. James, provost of King’s College (1905-1918), wrote stories in his spare time, yarns weaving his knowledge of antiquities together with the aberrant personalities (which were apparently more common in the nineteenth century), into stories of the supernatural. They are not easy reading. The stories ramble, focusing on physical detail without additional effect, rather like a drunk Henry James or a G. K. Chesterton without a sense of humor. Still, it’s fascinating to see what constituted scary a hundred years ago. Without the popularly-held image of what a ghost looks like, M. R. James describes them anew (one is characterized as a visage with its facial flesh burned off). Doom doesn’t last forever, either. The haunted manuscript acquired by an unsuspected dupe only temporarily brings its owner ill fate.
If Halloween is the time to experience the odd within the confines of the familiar, then M.R. James’ Ghost Stories are truly that. A glimpse of ancient days written from those very long ago days.
James, M. R. (Montague Rhodes), 1862-1936. Collected ghost stories. Oxford : Oxford University Press, 2011. Perkins/Bostock Library. PR6019 .A565 2011
Menri Monastery in Northern India possesses the world’s largest collection of manuscripts relating to Bön, the pre-Buddhist religion of Tibet. All photos by Edward Proctor.
Duke University has received a grant from the British Library’s Endangered Archives Programme to digitize and preserve a trove of ancient religious manuscripts related to Bön, the pre-Buddhist religion of Tibet.
Once digitized, the manuscripts will be made freely available online through the British Library, giving scholars around the world access to an important archive of religious texts that were previously accessible only by traveling to a monastery in a remote part of the Indian Himalayas.
The Menri Monastery, located near the village of Dolanji in the Northern Indian state of Himachal Pradesh, possesses the world’s largest collection of manuscripts relating to Bön. Most of these materials were rescued from ancient monasteries in Tibet before they were destroyed during the Chinese Cultural Revolution.
The collection includes some 129 pechas, or traditional Tibetan books, comprising more than 62,000 pages of text. A pecha consists of loose leaves of handmade paper wrapped in cloth, placed between wooden boards, and secured with a belt. Also included are some 479 handmade colorfully-illustrated initiation cards, or tsakli, which are employed in various rituals and contain significant amounts of text.
Duke librarian Edward Proctor, second from right, worked with monks at the monastery in 2009 to determine the feasibility of digitizing the Bön manuscripts.
As the name suggests, the British Library’s Endangered Archives Programme aims to preserve archival material that is in danger of disappearing, particularly in countries where resources and opportunities to preserve such material are lacking or limited. The Bön manuscripts are an excellent case in point, according to Edward Proctor, the principal investigator for the project. Proctor is Duke’s librarian for South and Southeast Asia. He also works to develop the South Asian Studies collection at the University of North Carolina at Chapel Hill Library through a cooperative arrangement with Duke.
“The Bön manuscripts are subject to a variety of perils,” said Proctor. “They are currently housed in a building that is neither air-conditioned nor humidity-controlled. Having so many unique materials in one location means that a single disaster, such as a massive mudslide or earthquake (not an infrequent occurrence in this area), could quickly extinguish the records of this ancient tradition.”
The Bön manuscripts cover a wide range of subjects, including history, grammar, poetry, rules of monastic discipline, rituals, astronomy, medicine, musical scores, biographies of prominent Bön teachers, and practical instruction manuals for the creation and consecration of paintings, sculptures, mandalas, ritual offerings, reliquaries, amulets, and talismans.
Proctor first traveled to the Menri Monastery in 2009 on a Pilot Project grant from the British Library to investigate the scope and condition of the Bön manuscripts and the feasibility of digitizing them. He will return later this fall and winter to oversee their digitization, which will be carried out by monastery staff. Proctor will provide training in digitization techniques and offer guidance on best practices in archival management. Once the project is complete, the digitization equipment funded by the British Library will remain at the monastery for the future use of the Bön monks.
Pechas, or traditional Tibetan books, consist of loose leaves of handmade paper wrapped in cloth, placed between wooden boards, and secured with a belt.
According to Proctor, this digitization project is essential to the efforts of Bön monks and nuns to preserve their unique culture, as well as the efforts of scholars elsewhere to understand the early cultural and intellectual history of Central Asia.
“These unique documents already escaped destruction once, during the excesses of the Cultural Revolution,” said Proctor. “But there is still a risk that they could disappear. Just last year, a fire in an 18th-century temple in Bhutan reduced its entire manuscript collection to ashes. Tragically, the temple’s collection had been proposed to be digitized as part of a Major Project grant. Thanks to this grant from the Endangered Archives Programme, it will now be possible to ensure the long-term survival of the Bön manuscripts in Menri Monastery.”
To learn more about the British Library’s Endangered Archives Programme, visit their website.
The collection also includes many tsakli, or handmade colorfully-illustrated initiation cards employed in various rituals.
Enter your research paper and you could win $1,000 cash!
The Lowell Aptman Prizes and Chester P. Middlesworth Awards were established by Duke University Libraries to reward excellence in research and writing. If you’re a Duke student, consider submitting a paper for one of these prizes—you could win $1,000!
The Aptman Prizes recognize undergraduates’ excellence in research, including their analysis, evaluation and synthesis of sources, and encourages students to make use of the general library collections and services at Duke University. Prizes are awarded in three categories (first- and second-year students, third-and fourth-year students, and fourth-year students working on an honors thesis), and each one comes with a cash award of $1,000. Funding for the awards has been generously provided by Eileen and Lowell (T’89) Aptman.
The Middlesworth Awards recognize excellence of research, analysis, and writing by Duke University students in the use of primary sources and rare materials held by the David M. Rubenstein Rare Book & Manuscript Library. Prizes are awarded in two categories (undergraduates and graduate students), and each one comes with a cash prize of $1,000. Funding for the awards has been generously provided by Chester P. Middlesworth (A.B., 1949) of Statesville, North Carolina.
The deadline for both awards is May 15, 2013.
All winners will be recognized at a reception held the Friday afternoon of Duke Family Weekend (October 25, 2013), where they will receive certificates and $1,000.
Revisiting the U.S. Naval Station, Guantánamo Bay, through the Duke University Libraries’ Caribbean Sea Migration Digital Collection
A “Mata de Navidad” (Christmas bush), constructed by Cuban detainees in a Guantánamo Bay tent city, 1994-1995.
When you hear the word “Guantánamo,” you probably don’t think of tent cities with families and children, religious festivals, and locally run newspapers.
But the Guantánamo Bay of the 1990s differed in many ways from the place Americans came to know after the September 11, 2001, terrorist attacks. Images of this earlier Guantánamo and its inhabitants, recently digitized by the Duke University Libraries, will soon be touring the country as part of an exhibit developed by the Guantánamo Public Memory Project, an initiative based at the Institute for the Study of Human Rights at Columbia University. The exhibit, opening in New York City on December 13 and touring the United States through 2014, explores the complex and controversial history of “Gitmo.”
Two Haitian boys are given a medical exam aboard the US Coast Guard cutter Chase by Chief Warrant Officer Paul Healey, in October 1981.
“We were fortunate to have advance access to the [Caribbean Sea Migration] collection, so that nearly 100 students at 11 universities across the country could use it extensively to prepare our traveling exhibit on the long history of the U.S. Naval Station at Guantánamo,” said Liz Ševčenko, Founding Director of the Guantánamo Public Memory Project and faculty member at the Institute. “It’s a tremendous resource for researchers and the general public.”
During the years 1991-1993 and again in 1994, tens of thousands of Haitians, fleeing political upheaval and repression, were interdicted by the U.S. Coast Guard and removed to the U.S. Naval Station at Guantánamo Bay, Cuba. While they awaited decisions on whether they would be repatriated to Haiti or allowed to apply for asylum in the U.S., the Haitians made a life in the tent cities established for them by the U.S. military.
In 1994 over 30,000 Cubans set out from Cuba by sea for the United States. Among them was Pavel Rodríguez, a nine-year-old boy who, along with his family, was interdicted by the U.S. Coast Guard and taken to Guantánamo. Pavel, who years later would enroll at Duke University Medical School, remembers both the anxiety arising from prolonged detention at GTMO and the sense of community among the refugees. Pavel recalls fellow Cubans at GTMO forming a newspaper at the camp and opening an art gallery, along with his own memories of “chasing iguanas and flying kites behind barbed wires and fences guarded by heavily armed soldiers.”
Draft of a news release for the camp publication Sa K’Pase, announcing an American-style summer camp for children in Guantánamo Camp IIA, 1992.
Stories like Pavel’s, and those of many others like him, make up the recently digitized Caribbean Sea Migration Collection, which documents the experiences of the more than 200,000 Haitians, Cubans and Dominicans who traversed the Caribbean Sea in the late 20th century, fleeing political instability in their home countries. Materials in this collection provide varying perspectives on Guantánamo in the late 20th century: from military personnel running the camps, to publishers of and contributors to community newspapers, to detainee-artists creating works reflective of their experience.
For more on the Guantánamo Public Memory Project traveling exhibit, visit their website and blog.
To learn more about the Caribbean Sea Migration and other collections digitized by the Duke University Libraries—which are made freely available for teaching, learning, and research—visit our digital collections website.
North Carolina has a long history of support and activism on behalf of immigrant communities. But only recently have immigrant activists begun to view their work from a human rights perspective.
That will be the topic of a community discussion on immigration and human rights at 5:30 p.m., November 12, in the Rare Book Room of Duke’s Perkins Library. “Harvesting a Legacy of Action: Immigration Activism and Human Rights” will feature a panel of experts discussing the challenges and possibilities of placing immigration activism within a human rights framework.
The panel will be moderated by Robin Kirk, co-director of the Duke Human Rights Center. Panelists will include Guadalupe Gamboa, Senior Program Officer for Worker Rights at Oxfam America; Ramon Zepeda, Youth Organizer for Student Action with Farmworkers and labor activist and organizer; and Paul Ortiz, History Professor at the University of Florida.
The panel discussion is part of a larger series of events around the state celebrating the 20th anniversary of Student Action with Farmworkers (SAF), a nonprofit organization that brings together students, community members, and farmworkers in the Southeast to work for justice in the agricultural system. What began as a small group of Duke Public Policy students documenting farmworker conditions has since grown to an independent nonprofit with a national impact. The organization’s papers are held by Duke’s Human Rights Archive in the David M. Rubenstein Rare Book & Manuscript Library.
Three exhibitions currently on display at the library explore the human experience of farmworkers and the history of SAF. The exhibits reflect historical and contemporary concerns with student activism, access to safe and healthy food, organized labor, and immigration. The exhibits run through December 9, 2012.
The exhibits and panel discussion are sponsored by SAF, the Duke University Libraries, the Center for Documentary Studies, the Franklin Humanities Institute BorderWorks Lab, the Duke University Service Learning Program, and the E. Rhodes and Leona B. Carpenter Foundation.
Date: Friday, October 26, 2012 Time: 5:00 p.m. Location: Thomas Room, Lilly Library, Duke East Campus (Map) Contact: Danette Pachtner, danette.p@duke.edu, 919-660-5886
Documentary Filmmaker Wu Wenguang
Join us for conversation and light refreshments with celebrated documentary filmmaker Wu Wenguang, one of the founding figures in Chinese independent documentary film. His work includes Bumming in Beijing, At Home in the World and most recently Treatment.
The talk is part of a series of presentations at Duke this week on The Memory Project. Four visiting Chinese filmmakers, including Wu Wenguang, screen their work on memories of the Great Famine (1959-1961). The Memory Project is based at Caochangdi Workstation in Beijing. From the Chinese capital, young filmmakers fanned out to return to family villages and their own pasts, real and imagined, to inquire about the Great Famine—a disaster whose memories have been actively abandoned by the state. But the films reveal as much about the wish for memory as of memory itself, and of the interesting role of film in such projects of retrieval.
Click here for complete film descriptions and screening information.
Alexander Kosolapov, “Untitled from Gorby Series.” From the Subverted Icon exhibit at the Nasher.
A new exhibit of post-Soviet artwork is currently on display in the Nasher Museum of Art’s Education Gallery through December 23, and it’s well worth a visit.
The exhibit, The Subverted Icon: Images of Power in Soviet Art (1970-1995),explores the ways in which artists in late- and post-Soviet Russia represented, confronted, and challenged state-sponsored propaganda, Soviet architecture, and the populist art of earlier generations. It was curated by students in Professor Pamela Kachurin’s “Soviet Art After Stalin” seminar. There’s a good review in the October 18 issue of the Duke Chronicle.
For those interested in a little extra credit, Duke is home to one of the oldest and most extensive Slavic research collections in the southeastern United States. Here’s a taste of some additional readings and resources to whet the appetite of your inner Russophile:
Americans in the Land of Lenin, a digitized collection of photographs of daily life in the Soviet Union (1919-1921 and 1930) drawn from the papers of Robert L. Eichelberger and Frank Whitson Fetter in the Rubenstein Rare Book & Manuscript Library.
Duke library users and Duke alumni will soon have a trove of new ebooks at their fingertips.
Approximately 1,500 scholarly monographs by Oxford University Press and its affiliates are now available as ebooks in the library catalog, with approximately 9,000 more to come later this year.
The development is part of an innovative deal brokered by Oxford University Press and the Triangle Research Libraries Network consortium (TRLN).
The ebooks are fully searchable and allow for unlimited user access, so that multiple people can read them at the same time. In addition, one shared print copy of each humanities and social science title will be held at Duke’s Library Service Center and be available for use by all TRLN institutions (Duke, UNC-Chapel Hill, NCSU, NCCU).
“The partnership allows for expanded access to scholarly material, with less overlap, at a lower cost to each TRLN institution,” says Aisha Harvey, Head of Collection Development at Duke University Libraries. “It also gives researchers the option of using a print or digital copy, depending on their personal preference.”
This access agreement is one of the first of its kind to allow shared e-book access among cooperating libraries. Another noteworthy aspect is that the ebooks will be fully available to all Duke alumni. Most ebooks in the Libraries’ collection are not accessible to alumni, due to copyright and licensing restrictions. But the new arrangement expands the Libraries’ offerings to Duke graduates. (A variety of library services and resources are already available for free to all Duke alumni, including some of our most popular databases.)
“The Triangle Research Libraries Network has a very long history of successful collaboration in building print collections,” said Sarah Michalak, University Librarian and Associate Provost at the University of North Carolina at Chapel Hill and chair of the TRLN Executive Committee.
Last year, with support from the Andrew W. Mellon Foundation, TRLN sponsored a “Beyond Print” summit to explore opportunities and challenges associated with ebook acquisitions and shared institutional access. The ebook deal with Oxford University Press is one outcome of those discussions.
“The agreement with OUP offers a welcome opportunity to experiment with approaches discussed at the summit, provide high-quality content to our users, and learn more about how students and researchers want to access scholarly output in a dual electronic-plus-print environment,” said Michalak.
Ebook and ejournal usage continues to rise in academic libraries across the country. In 2011, the Duke Libraries adopted an ebook advocacy model in order to guide collection decisions and advocate to publishers on behalf of researchers’ needs.
News, Events, and Exhibits from Duke University Libraries




 Lilly Gives its Loebs to Duke Students, Faculty, and Staff
Lilly Gives its Loebs to Duke Students, Faculty, and Staff



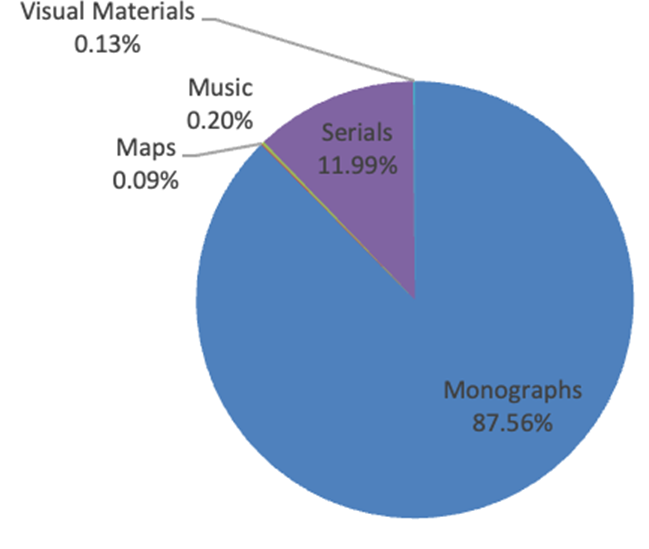
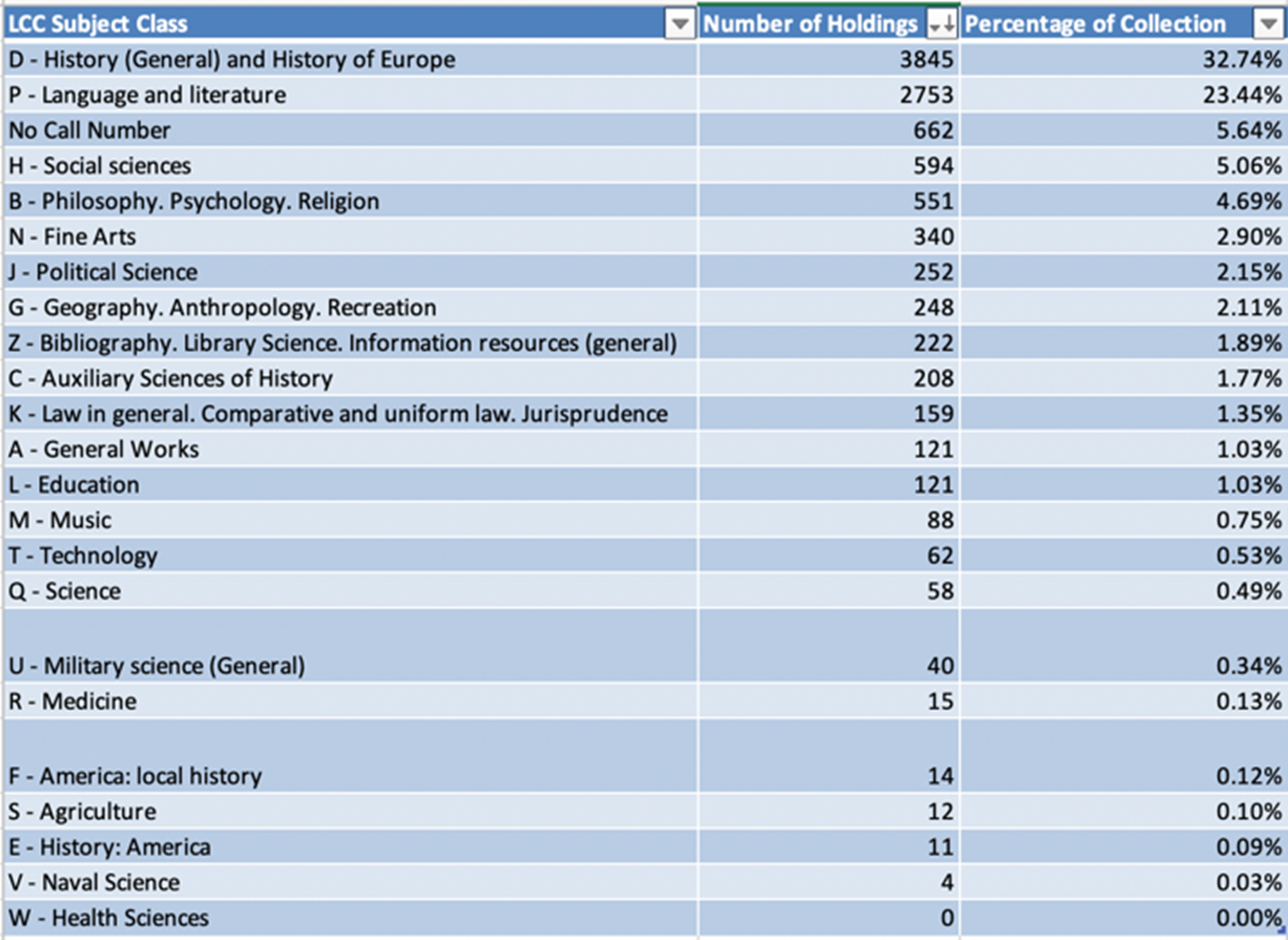


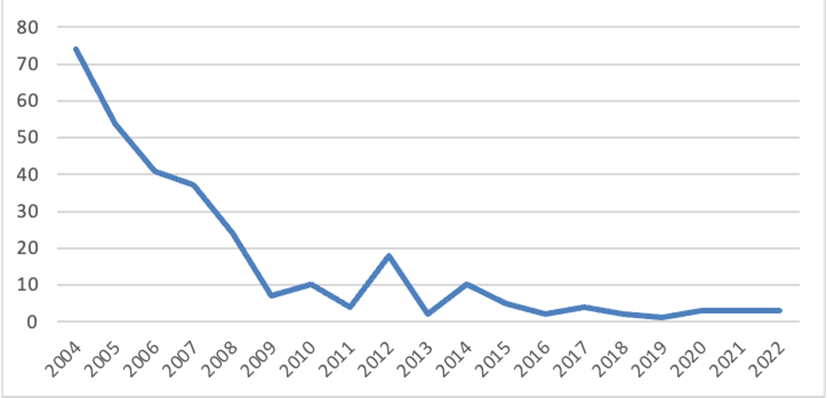




















 La Flor is an eight-part film, a decade in the making. It is an epic adventure in scale and imagination, a wildly entertaining ode to the power of storytelling. Filmed around the world, it is composed of six distinct episodes over eight parts, each starting the same four actresses. It redefines the concept of binge viewing.
La Flor is an eight-part film, a decade in the making. It is an epic adventure in scale and imagination, a wildly entertaining ode to the power of storytelling. Filmed around the world, it is composed of six distinct episodes over eight parts, each starting the same four actresses. It redefines the concept of binge viewing. 
 A captivating documentary about the ethics of activism in the modern media age. A River Below examines the efforts of two conservationists in the Amazon. One is a marine biologist and the other an animal activist and host of a popular National Geographic t.v. show. Their methods to save the pink river dolphin from extinction triggers unforeseen consequences.
A captivating documentary about the ethics of activism in the modern media age. A River Below examines the efforts of two conservationists in the Amazon. One is a marine biologist and the other an animal activist and host of a popular National Geographic t.v. show. Their methods to save the pink river dolphin from extinction triggers unforeseen consequences. A luminous short film by Matt Porterfield (SOLLERS POINT, PUTTY HILL) featuring rising star Barbara Lopez, CUATRO PAREDES follows Karla, recently arrived in Tijuana, Mexico to stay at her estranged aunt’s house a year after her father’s death. In this moment of solitude and calm, she looks up, down, inward and outward through the transpositional alchemy of text and is reminded that speaking to oneself feels like a vital human practice.
A luminous short film by Matt Porterfield (SOLLERS POINT, PUTTY HILL) featuring rising star Barbara Lopez, CUATRO PAREDES follows Karla, recently arrived in Tijuana, Mexico to stay at her estranged aunt’s house a year after her father’s death. In this moment of solitude and calm, she looks up, down, inward and outward through the transpositional alchemy of text and is reminded that speaking to oneself feels like a vital human practice.








 Yellowface
Yellowface























































































 Danette Pachtner
Danette Pachtner













 Richard H. Brodhead served as President of Duke University from 2004 to 2017. As President, he advanced an integrative, engaged model of undergraduate education and strengthened Duke’s commitment to access and opportunity, raising nearly $1 billion for financial aid endowment. Under his leadership, Duke established many of its best-known international programs, including the Duke Global Health Institute, DukeEngage, and Duke Kunshan University. Closer to home, Duke completed major renovations to its historic campus and played a crucial role in the revitalization of downtown Durham.
Richard H. Brodhead served as President of Duke University from 2004 to 2017. As President, he advanced an integrative, engaged model of undergraduate education and strengthened Duke’s commitment to access and opportunity, raising nearly $1 billion for financial aid endowment. Under his leadership, Duke established many of its best-known international programs, including the Duke Global Health Institute, DukeEngage, and Duke Kunshan University. Closer to home, Duke completed major renovations to its historic campus and played a crucial role in the revitalization of downtown Durham.








 Featuring collector and exhibit co-curator Lisa Unger Baskin in conversation with Naomi L. Nelson, Associate University Librarian and Director, Rubenstein Library. Also featuring introductory remarks by Edward Balleisen, Vice Provost for Interdisciplinary Studies. Free and open to the public.
Featuring collector and exhibit co-curator Lisa Unger Baskin in conversation with Naomi L. Nelson, Associate University Librarian and Director, Rubenstein Library. Also featuring introductory remarks by Edward Balleisen, Vice Provost for Interdisciplinary Studies. Free and open to the public.




















































 What is African literature? Is it literature created by Africans or about Africans? These are some of the questions students in the Duke Africa Conversations Club hope to spark in their selection of books for Duke University Libraries’ current Collection Spotlight on Contemporary African Literature.
What is African literature? Is it literature created by Africans or about Africans? These are some of the questions students in the Duke Africa Conversations Club hope to spark in their selection of books for Duke University Libraries’ current Collection Spotlight on Contemporary African Literature. The Africa Conversations Club encourages discourse at Duke about issues relating to the African continent and the African diaspora. Their selections (chosen in consultation with Heather Martin, African and African American Studies Librarian) highlight contemporary African fiction, nonfiction, and poetry.
The Africa Conversations Club encourages discourse at Duke about issues relating to the African continent and the African diaspora. Their selections (chosen in consultation with Heather Martin, African and African American Studies Librarian) highlight contemporary African fiction, nonfiction, and poetry.

























































 Join the Duke University Libraries as we celebrate the opening of the
Join the Duke University Libraries as we celebrate the opening of the 


























")













