We’re excited to have released nine digitized collections online this week in the Duke Digital Repository (see the list below ). Some are brand new, and the others have been migrated from older platforms. This brings our tally up to 27 digitized collections in the DDR, and 11,705 items. That’s still just a few drops in what’ll eventually be a triumphantly sloshing bucket, but the development and outreach we completed for this batch is noteworthy. It changes the game for our ability to put digital materials online faster going forward.
Let’s have a look at the new features, and review briefly how and why we ended up here.
Collection Portals: No Developers Needed
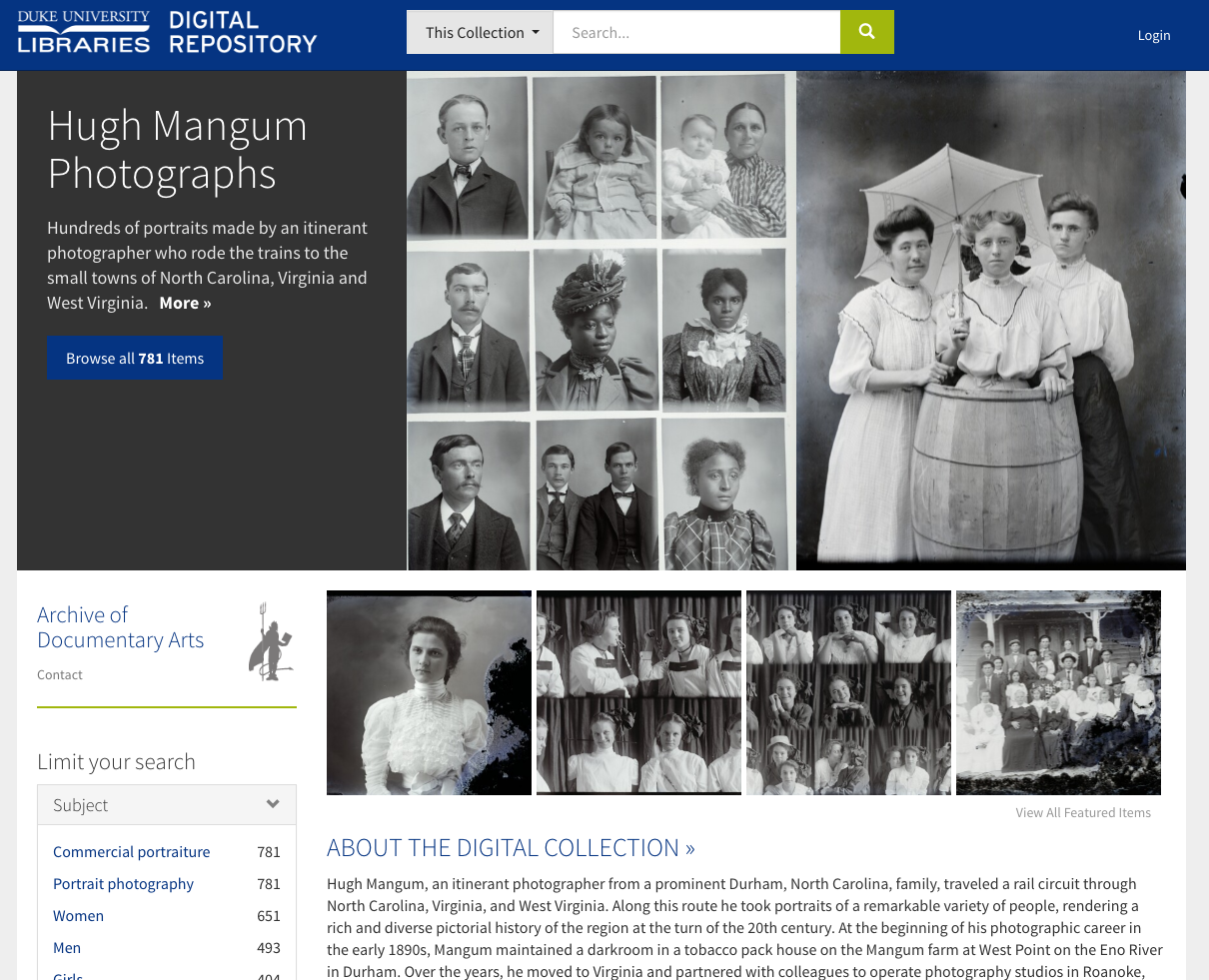
Before this week, each digital collection in the DDR required a developer to create some configuration files in order to get a nice-looking, made-to-order portal to the collection. These configs set featured items and their layout, a collection thumbnail, custom rules for metadata fields and facets, blog feeds, and more.

It’s helpful to have this kind of flexibility. It can enhance the usability of collections that have distinctive characteristics and unique needs. It gives us a way to show off photos and other digitized images that’d otherwise look underwhelming. But on the other hand, it takes time and coordination that isn’t always warranted for a collection.
We now have an optimized default portal display for any digital collection we add, so we don’t need custom configuration files for everything. A collection portal is not as fancy unconfigured, but it’s similar and the essential pieces are present. The upshot is: the digital collections team can now take more items through the full workflow quickly–from start to finish–putting collections online without us developers getting in the way.

Folder Items
To better accommodate our manuscript collections, we added more distinction in the interface between different kinds of image items. A digitized archival folder of loose manuscript material now includes some visual cues to reinforce that it’s a folder and not, e.g., a bound album, a single photograph, or a two-page letter.

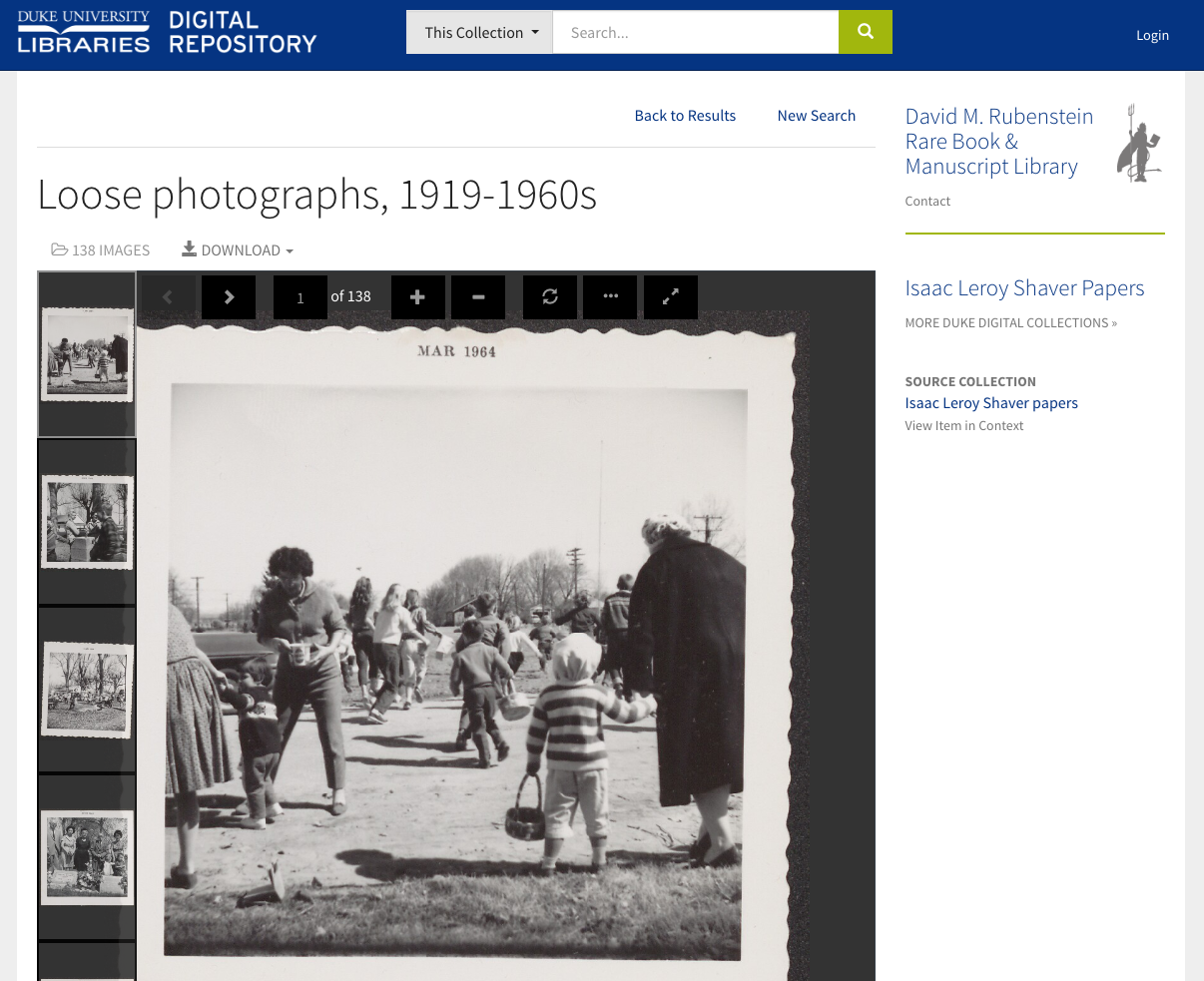
We completed a fair amount of folder-level digitization in recent years, especially between 2011-2014 as part of a collaborative TRLN Large-Scale Digitization IMLS grant project. That initiative allowed us to experiment with shifting gears to get more digitized content online efficiently. We succeeded in that goal, however, those objects unfortunately never became accessible or discoverable outside of their lengthy, text-heavy archival collection guides (finding aids). They also lacked useful features such as zooming, downloading, linking, and syndication to other sites like DPLA. They were digital collections, but you couldn’t find or view them when searching and browsing digital collections.
Many of this week’s newly launched collections are composed of these digitized folders that were previously siloed off in finding aids. Now they’re finally fully integrated for preservation, discovery, and access alongside our other digital collections in the DDR. They remain viewable from within the finding aids and we link between the interfaces to provide proper context.
Keyboard Nav & Rotation
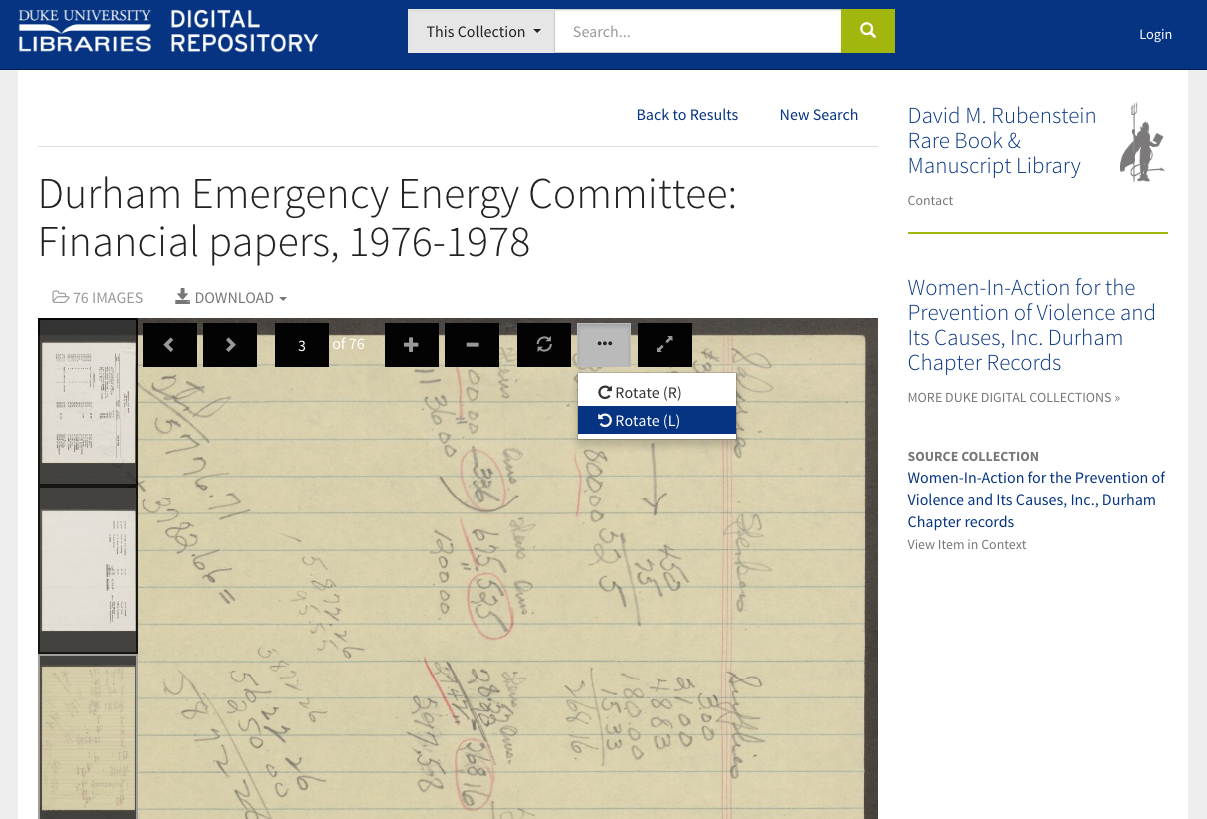
Two things are bound to increase when digitizing manuscripts en masse at the folder level: 1) the number of images present in any given “item” (folder); 2) the chance that something of interest within those pages ends up oriented sideways or upside-down. We’ve improved the UI a bit for these cases by adding full keyboard navigation and rotation options.
Conclusion
Duke Libraries’ digitization objectives are ambitious. Especially given both the quality and quantity of distinctive, world-class collections in the David M. Rubenstein Library, there’s a constant push to: 1) Go Faster, 2) Do More, 3) Integrate Everything, and 4) Make Everything Good. These needs are often impossibly paradoxical. But we won’t stop trying our best. Our team’s accomplishments this week feel like a positive step in the right direction.