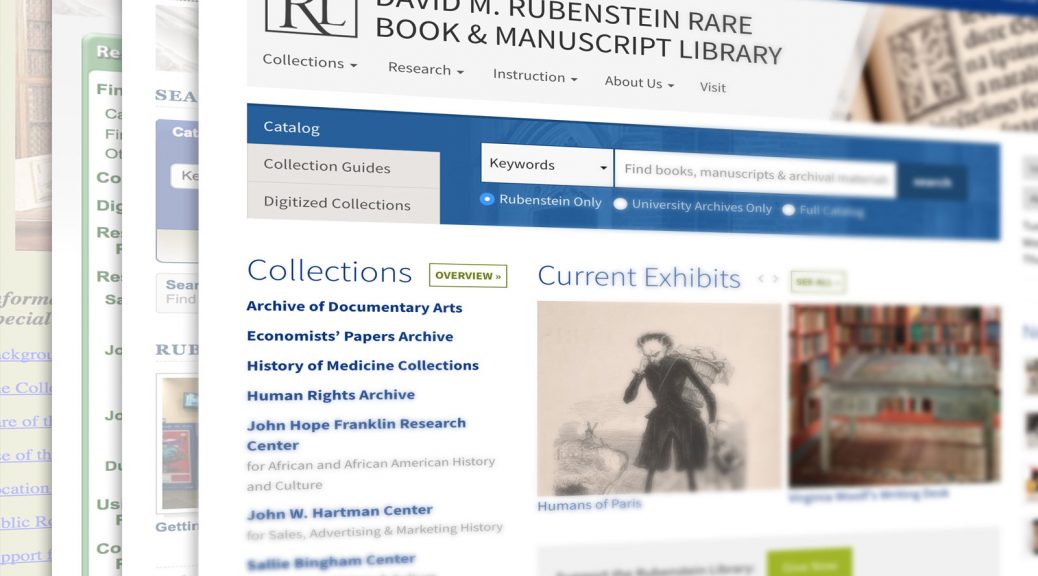
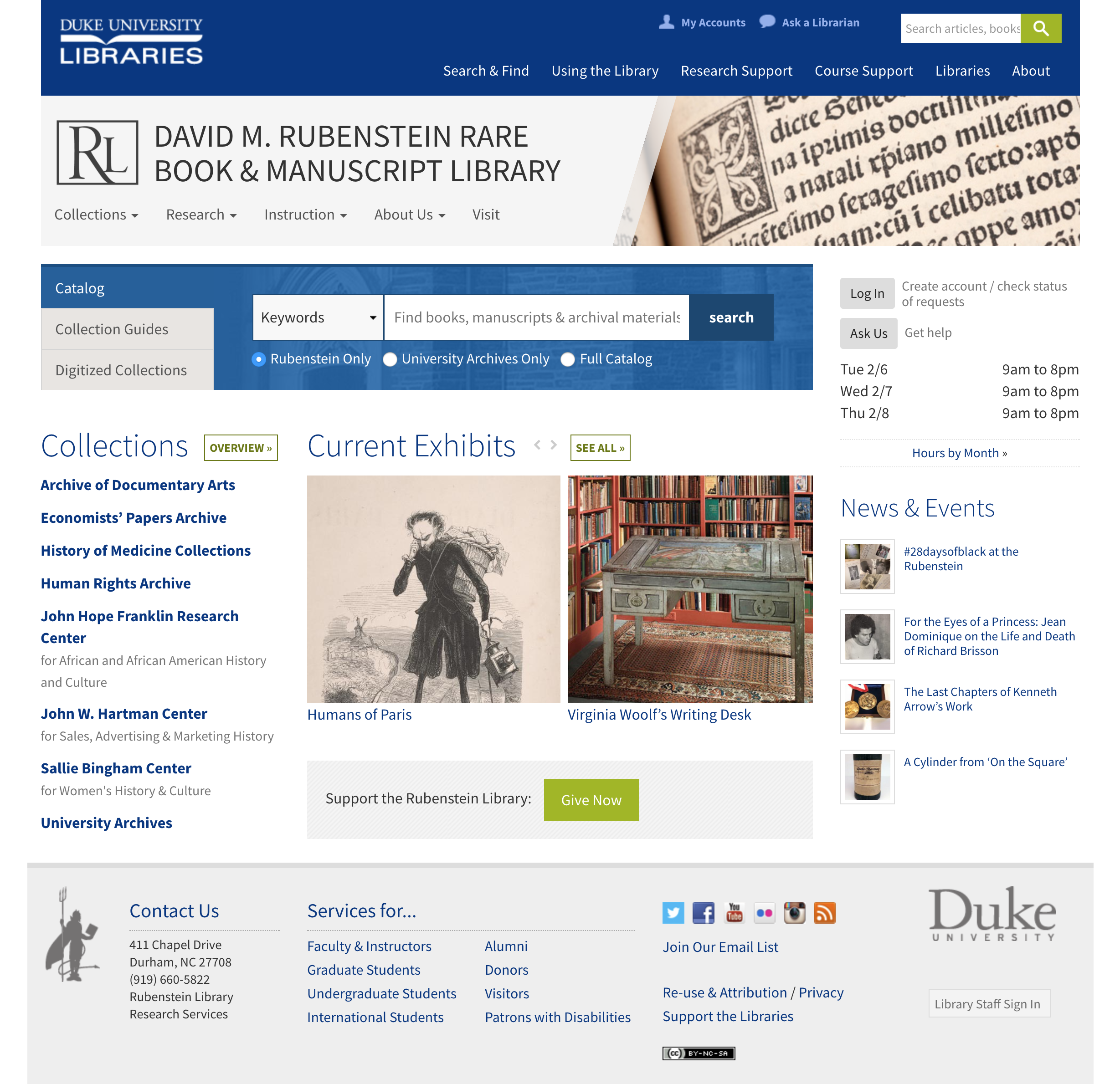
We kicked off the spring 2018 semester by rolling out a brand-new design for the David M. Rubenstein Library website. The new site features updated imagery from the collections, better navigation, and more prominent presence for the exhibits currently on display.
Much credit goes to Katie Henningsen and Kate Collins who championed the project.
Objectives for the Redesign
- Make wayfinding from the homepage clearer (by reorganizing links into a primary dropdown navigation)
- Dynamically feature Rubenstein Library exhibits that are currently on display
- Improve navigation to key Rubenstein site pages from within research center / collection pages
- Display larger images illustrative of the library’s distinctive and diverse collections
- Retain aspects of the homepage that have been effective, e.g., hours and resource search boxes
- Improve the site aesthetic
Internal Navigation
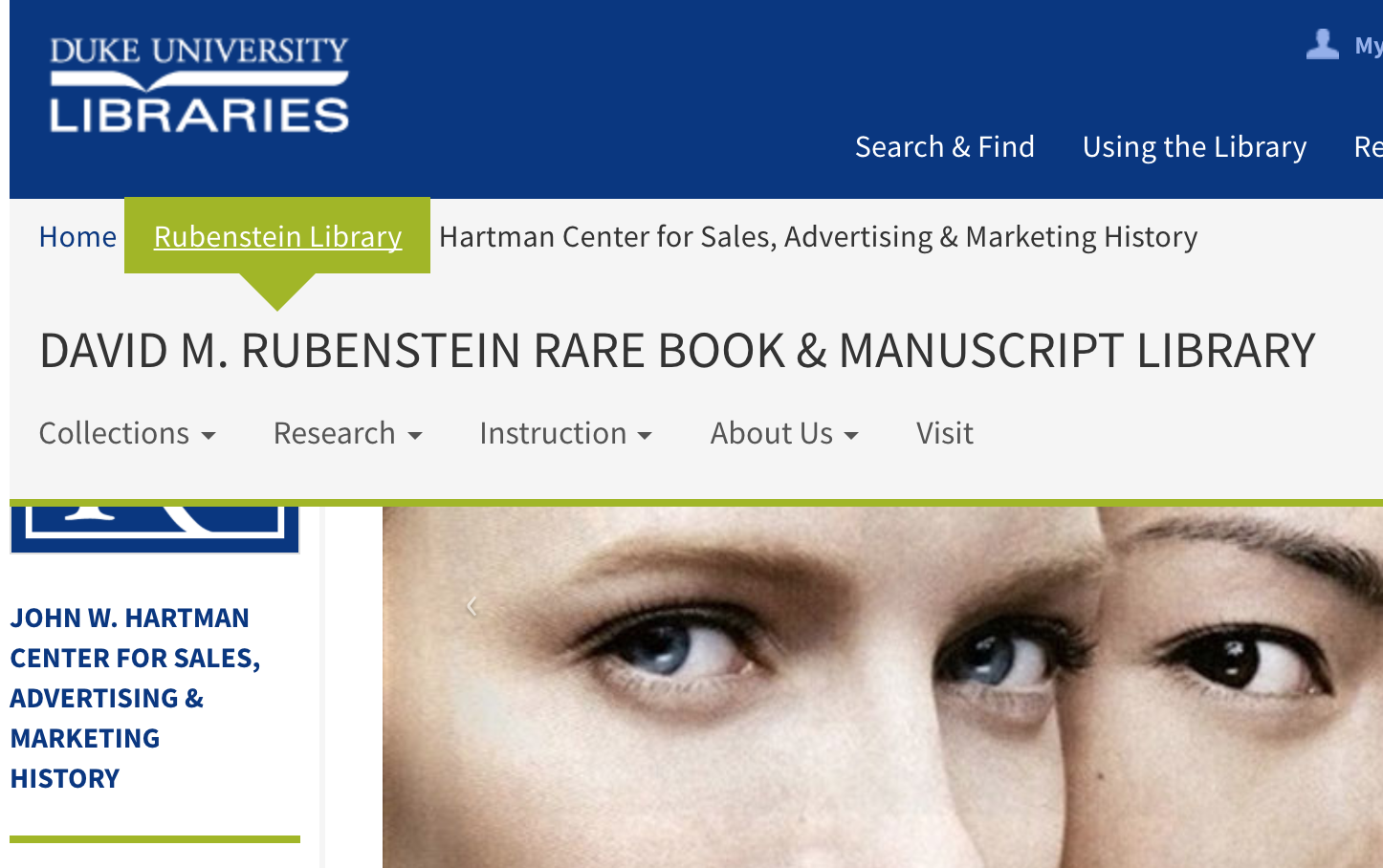
With a new primary navigation in hand on the Rubenstein homepage that links to key pages in the site, we began to explore ways to get visitors to those links in an unobtrusive way when they aren’t on the homepage. Each research center within the library, e.g., the John W. Hartman Center for Sales, Advertising & Marketing History, has its own sub-site with its own secondary menus, which already contend a bit with the blue Duke Libraries menu in the masthead. To avoid burying visitors in a Russian nesting doll of navigation, we decided to try dropping the RL menu down from the breadcrumb trail link so it’s tucked away, but still accessible when needed. We’re eager to learn whether or not this is effective.
A Look Back
Depending on how you count, this is now the seventh or eighth homepage design for the Rubenstein Library (formerly the Rare Book, Manuscript, and Special Collections Library; formerly the Special Collections Library). I thought I’d take a quick stroll down memory lane, courtesy of the Internet Archive’s Wayback Machine, to reflect on how far we have come over the years.
1996
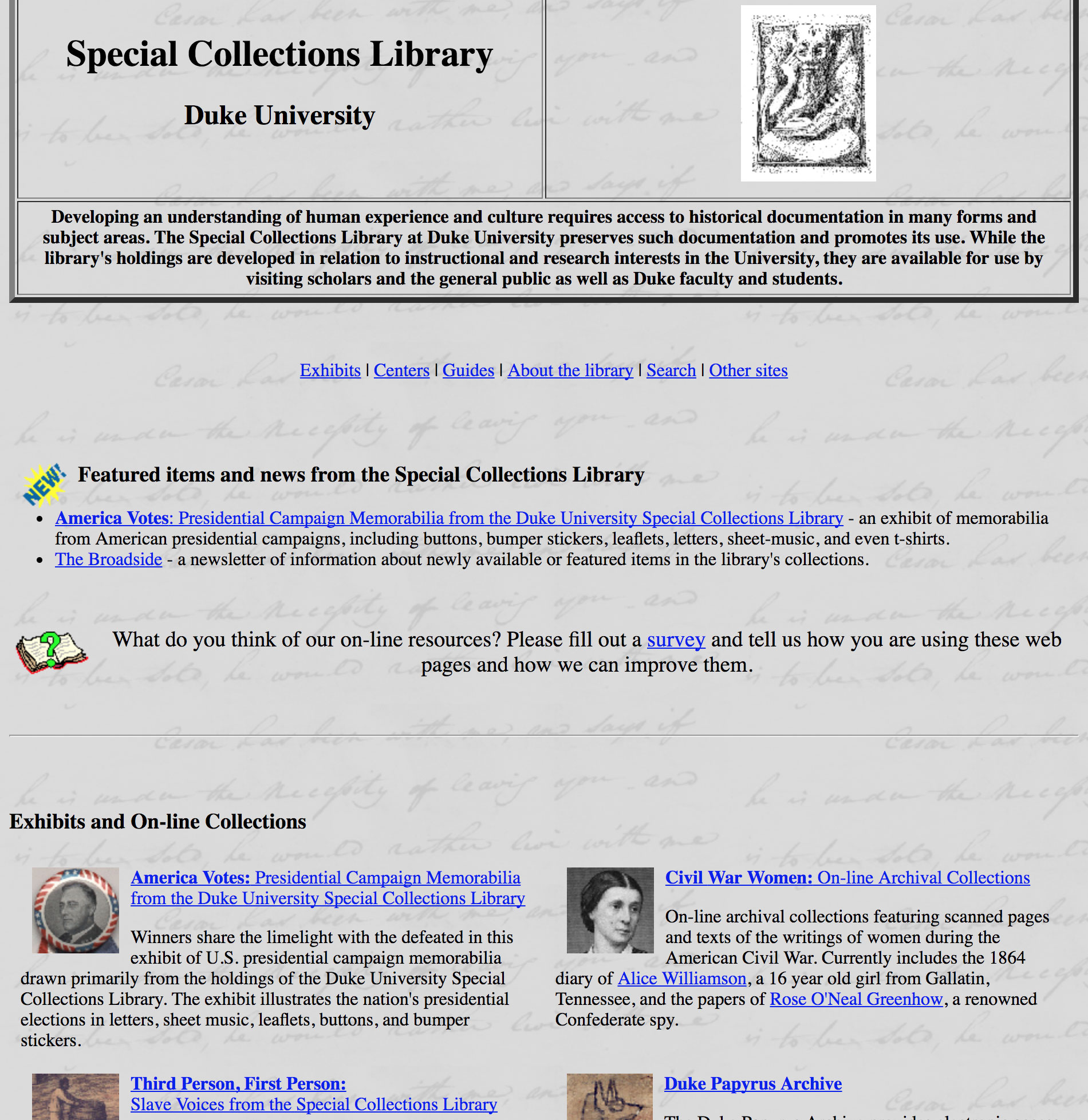
Features:
- prominent news, exhibits, and online collections
- links to online SGML- and HTML-encoded finding aids (42 of them!)
- a site search box powered by Excite!
1997

Features:
- two-column layout with a left-hand nav
- digitized collections
- a special collections newsletter called The Broadside
- became the “Rare Book, Manuscript, and Special Collections Library” in 1997
2005

Features:
- color-coded navigation broken into three groups of links
- image from the collections
- featured exhibit with image
- rounded corners and shadows
- first use of a CMS (content management system named Cascade Server)*
2007

Features:
- first time sharing a masthead with rest of the Duke University Libraries
- retained the lists of links, single collection image, and featured exhibit from previous iteration
2011

Features:
- renamed as the David M. Rubenstein Rare Book & Manuscript Library
- first time with catalog and finding aids search boxes on the homepage
- first appearance of social media & RSS icons
- first iteration to display library hours
- first news carousel appearance
2014

Features:
- new site in Drupal content management system
- first responsive RL website (works well on mobile devices)
- array of vertical image panels from the collections
- extended color palette to match Duke University website styles (at the time)
- gradients and rounded buttons with shadows
- first time able to search digital collections from RL homepage
- first site with Login button for Aeon (Special Collections request system)
2017

Features:
- updated all fonts and colors as part of a website “refresh” project
- used a flat aesthetic removing gradients, shadows, rounded corners
2018
Features
- lightened the overall aesthetic
- featured image cycling from selections at random (diagonally sliced using css clip-path polygons)
- prominent current exhibits feed with images
- a primary nav with dropdown menus
How long will this latest edition of the Rubenstein Library homepage stick around? Only time will tell, but we’ll surely continue to iterate, learn from the past, and improve with each attempt. For now, we’re pleased with the new site, and hope you will be as well.
* Revised Feb 9, 2018 to reflect that the first version using a content management system was in 2005 rather than 2007.