

Why research data? Data generated by scholars in the course of investigation are increasingly being recognized as outputs nearly equal in importance to the scholarly publications they support. Among other benefits, the open sharing of research data reinforces unfettered intellectual inquiry, fosters reproducibility and broader analysis, and permits the creation of new data sets when data from multiple sources are combined. Data sharing, though, starts with data curation.
In January of this year, Duke University Libraries brought on four new staff members–two Research Data Management Consultants and two Digital Content Analysts–to engage in this curatorial effort, and we have spent the last few months mapping out and refining a research data curation workflow to ensure best practices are applied to managing data before, during, and after ingest into the Duke Digital Repository.
What does this workflow entail? A high level overview of the process looks something like the following:
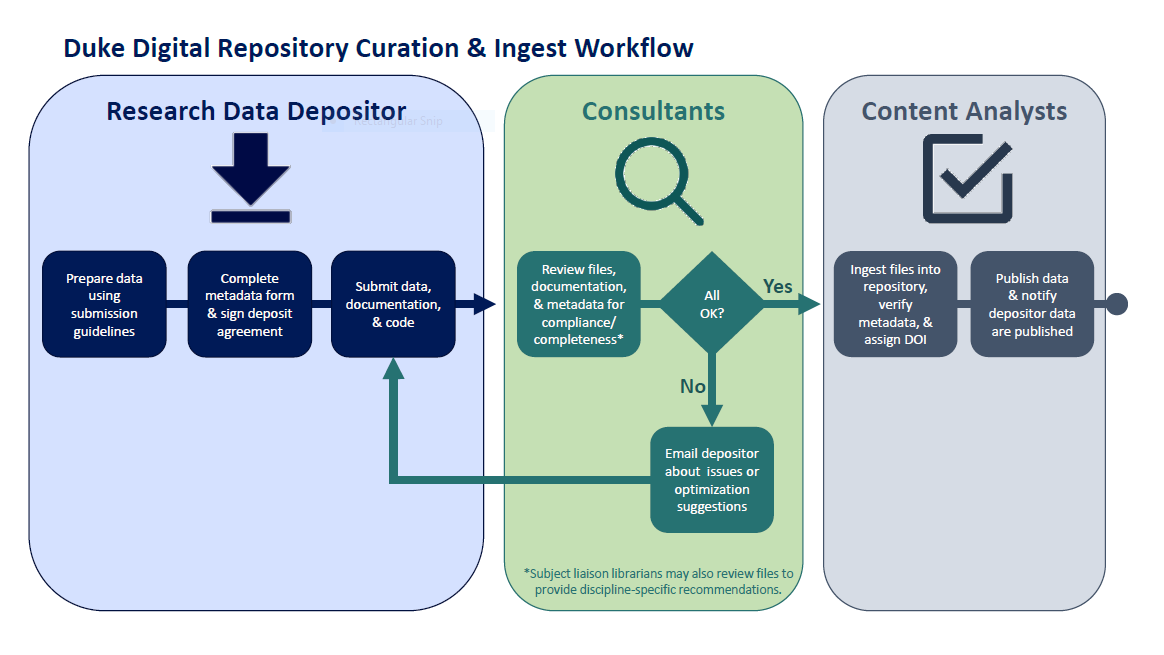
After collecting their data, the researcher will take what steps they are able to prepare it for deposit. This generally means tasks like cleaning and de-identifying the data, arranging files in a structure expected by the system, and compiling documentation to ensure that the data is comprehensible to future researchers. The Research Data Management Consultants will be on hand to help guide these efforts and provide researchers with feedback about data management best practices as they prepare their materials.
Depositors will then be asked to complete a metadata form and electronically sign a deposit agreement defining the terms of deposit. After we receive this information, someone from our team will invite the depositor to transfer their files to us, usually through Box.

As this stage, the Research Data Management Consultants will begin a preliminary review of the researcher’s data by performing a cursory examination for personally identifying or protected health information, inspecting the researcher’s documentation for comprehension and completeness, analyzing the submitted metadata for compliance with the research data application profile, and evaluating file formats for preservation suitability. If they have any concerns, they will contact the researcher to make some suggestions about ways to better align the deposit with best practices.

When the deposit is in good shape, the Research Data Management Consultants will notify the Digital Content Analysts, who will finalize the file arrangement and migrate some file formats, generate and normalize any necessary or missing metadata, ingest the files into the repository, and assign the deposit a DOI. After the ingest is complete, the Digital Content Analysts will carry out some quality assurance on the data to verify that the deposit was appropriately and coherently structured and that metadata has been correctly assigned. When this is confirmed, they will publish the data in the repository and notify the depositor.
Of course, this workflow isn’t a finished piece–we hope to continue to clarify and optimize the process as we develop relationships with researchers at Duke and receive more data. The Research Data Management Consultants in particular are enthusiastic about the opportunity to engage with scholars earlier in the research life cycle in order to help them better incorporate data curation standards in the beginning phases of their projects. All of us are looking forward to growing into our new roles, while helping to preserve Duke’s research output for some time to come.